使用 LangChain 和 Gemini 2.0 实现 Agentic RAG
在 2024 年,随着 RAG(检索增强生成)的兴起,AI Agent 作为一项变革性技术出现。让我们从宏观角度了解 AI Agent 及其重要性。AI Agent 是将大型语言模型(LLM)的推理能力与记忆和外部工具(例如 API、数据库和网络搜索引擎)结合的工作流。通过这些工具,AI Agent 能够规划并执行多步工作流,从而自主完成复杂任务。访问外部知识源动态决定何时以及如何检索信息基于推理

在 2023 年,检索增强生成(RAG)成为人工智能领域最受关注的突破之一,彻底改变了系统 Agent 上下文和知识的方式。
2024 年则被称为 AI Agent 的时代,它为构建更具自主性和交互性的应用程序开辟了令人兴奋的可能性。
如果您刚刚接触生成式 AI,对 RAG 还不熟悉,不必担心——本文将为您提供必要的基础知识,并介绍一个高级概念:Agentic RAG(代理化 RAG)。
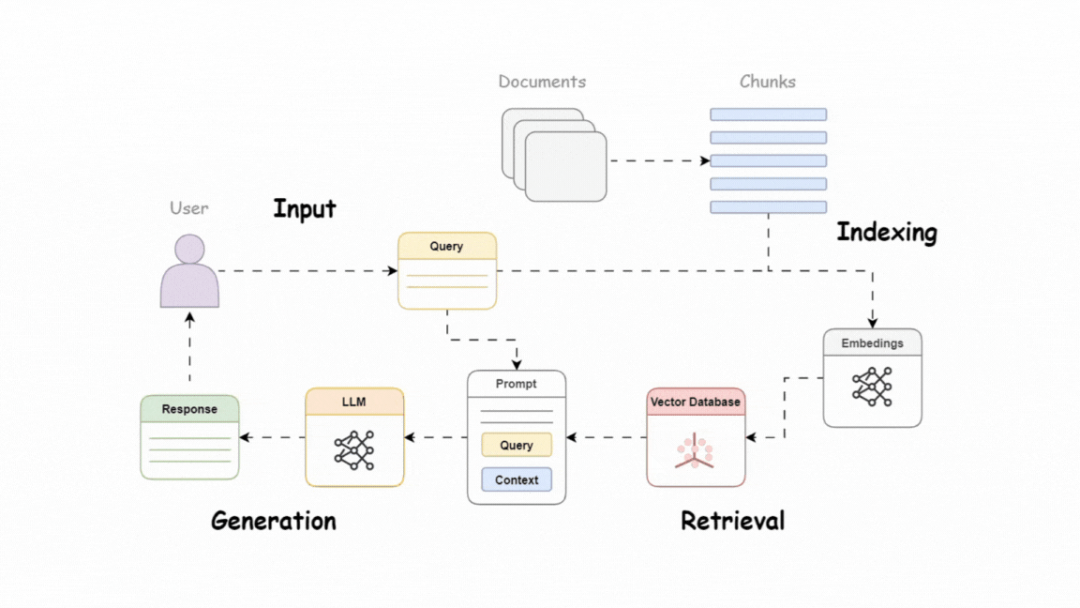
RAG :基础知识
大型语言模型(LLMs)非常强大,但它们也有一个局限性:缺乏记忆能力。可以将它们想象成基于预训练知识生成响应的巨大生成器。尽管这对一般性回答已经足够,但如果您需要针对私人或特定数据集的答案,该怎么办?这时,RAG 就登场了。
RAG 通过整合外部知识库,使 LLM 能够检索并生成与上下文相关的响应,这些知识库包括:
- 向量数据库
- 结构化知识源
- API 或其他自定义工具
一、什么是 AI Agent?
在 2024 年,随着 RAG(检索增强生成)的兴起,AI Agent 作为一项变革性技术出现。让我们从宏观角度了解 AI Agent 及其重要性。
AI Agent 是将大型语言模型(LLM)的推理能力与记忆和外部工具(例如 API、数据库和网络搜索引擎)结合的工作流。通过这些工具,AI Agent 能够规划并执行多步工作流,从而自主完成复杂任务。
通过将这些工作流与检索系统整合,可以创建一个“代理化的 RAG”管道,它能够:
- 访问外部知识源
- 动态决定何时以及如何检索信息
- 基于推理和检索路径调整响应
设想一个 AI Agent,它可以根据用户查询动态决定是否从向量数据库中检索数据、执行网络搜索,或者直接生成响应。
二、Agentic RAG 的基础
Agentic RAG 是将检索增强生成与 Agent 融合,使检索过程具备决策和推理能力。
其工作原理如下:
-
检索变得代理化
代理(路由器)使用不同的检索工具(例如向量搜索或网络搜索),并根据上下文动态决定调用哪个工具。 -
动态路由
代理(路由器)确定最佳路径。例如:
- 如果用户查询需要私人知识,它可能调用向量数据库。
- 对于一般查询,它可能选择网络搜索或依赖预训练知识。
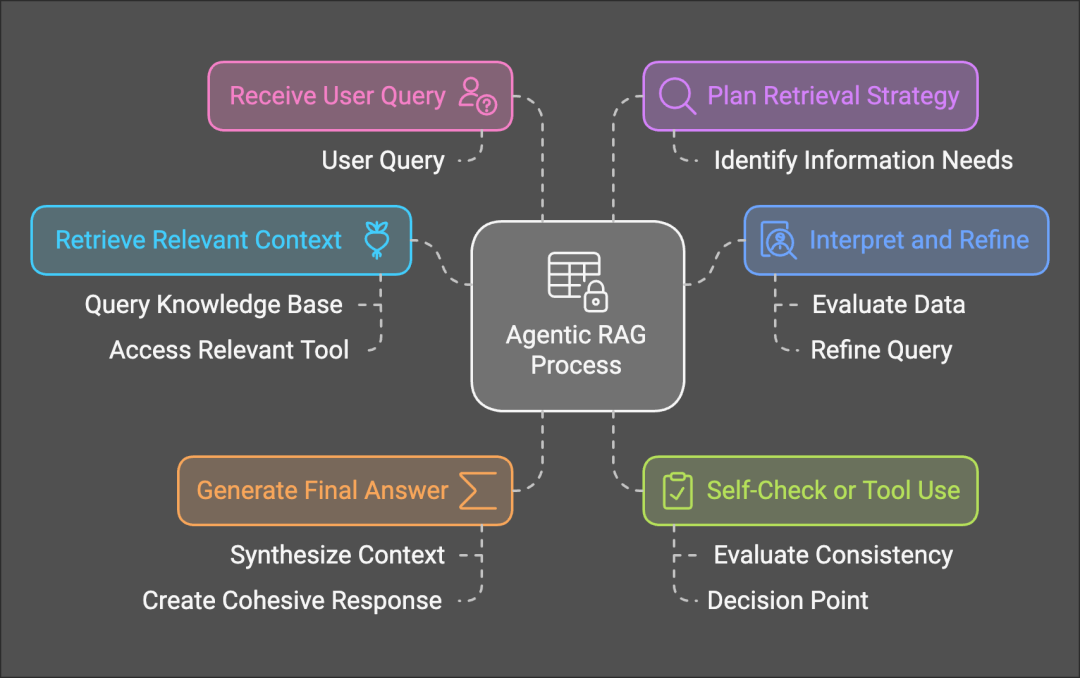
这种架构将 RAG 转变为一个更智能、更适应性强的管道,用于构建复杂的 AI 系统。
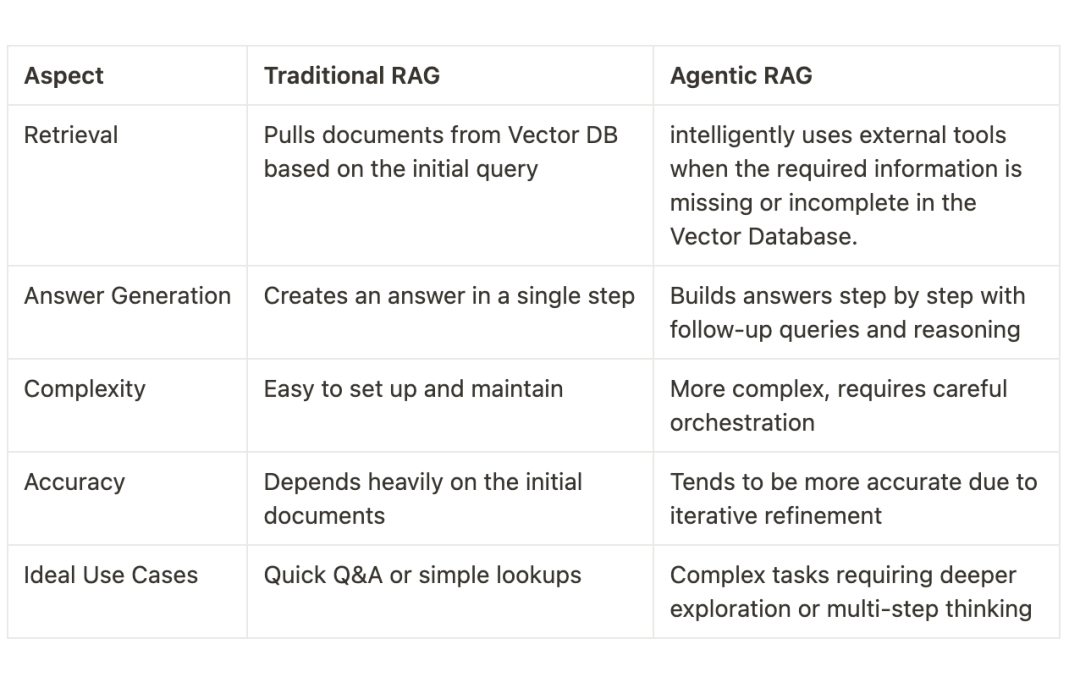
三、传统 RAG 与代理化 RAG 的比较
传统 RAG 是一种简单的一次性流程:系统接收到一个问题后,从向量存储中提取最相关的文档,然后立即生成答案。这种方法有时会遗漏重要细节,或者过于依赖检索过程中获取的文档内容。
代理化 RAG 则是一种更智能的方法。它不仅检索文档,还利用工具搜索更多信息,并通过逐步构建的方式生成最终答案。
这种方法更加精准且灵活。
四、实现:设置 Agentic RAG
我们发布了一份 Google Colab 笔记本,展示了一个基本的Agentic RAG 管道的实践操作。下面我们将逐步讲解代码,帮助您快速入门。
1. 安装库并设置环境
在开始实现之前,请确保已安装必要的库并配置环境变量:
# install dependencies
!pip install --upgrade --quiet athina-client langchain langchain_community langchain-google-genai pypdf faiss-gpu langchain-huggingface
# set api key
import os
from google.colab import userdata
os.environ['ATHINA_API_KEY'] = userdata.get('ATHINA_API_KEY')
os.environ['TAVILY_API_KEY'] = userdata.get('TAVILY_API_KEY')
os.environ["GOOGLE_API_KEY"] = userdata.get('GOOGLE_API_KEY')
2. 加载文档并准备嵌入
接下来,加载您的文档(例如 PDF),并为检索做好准备。将文档拆分为带有重叠的块,以便更好地进行上下文检索。
# load pdf
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/tesla_q3.pdf")
documents = loader.load()
# split documents
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
documents = text_splitter.split_documents(documents)
# load embedding model
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5", encode_kwargs = {"normalize_embeddings": True})
3. 使用 FAISS 创建向量存储
现在,创建一个向量存储,用于存储文档嵌入,以实现高效的相似性搜索。
# # create vectorstore
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(documents, embeddings)
# # saving the vectorstore
# vectorstore.save_local("vectorstore.db")
4. 设置检索器
从向量存储中定义检索器。
# create retriever
retriever = vectorstore.as_retriever()
5. Web Search
We’ll use Tavily for the web search component
# define web search
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=10)
6. 设置LLM
# load llm
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash-exp")
7. 创建工具函数
# define vector search
from langchain.chains import RetrievalQA
def vector_search(query: str):
qa_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
return qa_chain.run(query)
# define web search
def web_search(query: str):
return web_search_tool.run(query)
8. 创建并定义 Agent 的工具
配置 Agent 可以使用的工具,例如向量检索器和网络搜索:
# create tool call for vector search and web search
from langchain.tools import tool
@tool
def vector_search_tool(query: str) -> str:
"""Tool for searching the vector store."""
return vector_search(query)
@tool
def web_search_tool_func(query: str) -> str:
"""Tool for performing web search."""
return web_search(query)
# define tools for the agent
from langchain.agents import Tool
tools = [
Tool(
name="VectorStoreSearch",
func=vector_search_tool,
description="Use this to search the vector store for information."
),
Tool(
name="WebSearch",
func=web_search_tool_func,
description="Use this to perform a web search for information."
),
]
9. 为 Agent 创建提示词
为 Agent 定义一个系统提示,以在执行过程中遵循:
# define system prompt
system_prompt = """Respond to the human as helpfully and accurately as possible. You have access to the following tools: {tools}
Always try the \"VectorStoreSearch\" tool first. Only use \"WebSearch\" if the vector store does not contain the required information.
Use a json blob to specify a tool by providing an action key (tool name) and an action_input key (tool input).
Valid "action" values: "Final Answer" or {tool_names}
Provide only ONE action per
JSON_BLOB
# human prompt
human_prompt = """{input}
{agent_scratchpad}
(reminder to always respond in a JSON blob)"""
# create prompt template
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human_prompt),
]
)
# tool render
from langchain.tools.render import render_text_description_and_args
prompt = prompt.partial(
tools=render_text_description_and_args(list(tools)),
tool_names=", ".join([t.name for t in tools]),
)
10. 构建 RAG 链和 Agent
将所有内容整合在一起,创建 RAG 管道和Agent:
# create rag chain
from langchain.schema.runnable import RunnablePassthrough
from langchain.agents.output_parsers import JSONAgentOutputParser
from langchain.agents.format_scratchpad import format_log_to_str
chain = (
RunnablePassthrough.assign(
agent_scratchpad=lambda x: format_log_to_str(x["intermediate_steps"]),
)
| prompt
| llm
| JSONAgentOutputParser()
)
# create agent
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(
agent=chain,
tools=tools,
handle_parsing_errors=True,
verbose=True
)
11. 调用 Agent
最后就是传递用户查询到 Agent 并从 Agentic RAG 获得结果。
Query:
agent_executor.invoke({"input": "Total automotive revenues Q3-2024"})
Response:
> Entering new AgentExecutor chain...
Thought: I need to find the total automotive revenues for Q3 2024. I should first check my vector store for this information.
Action:
{
"action": "VectorStoreSearch",
"action_input": "Total automotive revenues Q3-2024"
}
Total automotive revenues in Q3-2024 were $20,016 million.
Action:
{
"action": "Final Answer",
"action_input": "Total automotive revenues in Q3-2024 were $20,016 million."
}
> Finished chain.
{'input': 'Total automotive revenues Q3-2024',
'output': 'Total automotive revenues in Q3-2024 were $20,016 million.'}
12. 执行多个查询
你可以通过传递一个问题的数组来处理批量查询。
# create agent with verbose=False for production
agent_output = AgentExecutor(
agent=chain,
tools=tools,
handle_parsing_errors=True,
verbose=False
)
# Create dataset
question = [
"What milestones did the Shanghai factory achieve in Q3 2024?",
"Tesla stock market summary for 2024?"
]
response = []
contexts = []
# Inference
for query in question:
vector_contexts = retriever.get_relevant_documents(query)
if vector_contexts:
context_texts = [doc.page_content for doc in vector_contexts]
contexts.append(context_texts)
else:
print(f"[DEBUG] No relevant information in vector store for query: {query}. Falling back to web search.")
web_results = web_search_tool.run(query)
contexts.append([web_results])
# Get the agent response
result = agent_output.invoke({"input": query})
response.append(result['output'])
# To dict
data = {
"query": question,
"response": response,
"context": contexts,
}
五、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 31
31 0
0- 0



 已为社区贡献102条内容
已为社区贡献102条内容

所有评论(0)