operator: openai CUA agent原理介绍
继去年10月底Anthropic发布Claude 3.5的computer use能力之后,OpenAI在今年1月24日也发布了计算机使用agent(Computer-Using Agent, CUA)模型——Operator。这一模型结合了GPT-4o的视觉能力和通过强化学习获得的高级推理能力,能够解释截图并与图形用户界面(GUI)进行交互。它不仅能够执行日常任务,如在线购物、预订餐厅或购买活动
继去年10月底Anthropic发布Claude 3.5的computer use能力之后,OpenAI在今年1月24日也发布了计算机使用agent(Computer-Using Agent, CUA)模型——Operator。这一模型结合了GPT-4o的视觉能力和通过强化学习获得的高级推理能力,能够解释截图并与图形用户界面(GUI)进行交互。它不仅能够执行日常任务,如在线购物、预订餐厅或购买活动门票,还能够在用户的指导和监督下完成更复杂的任务。
工作原理
Operator模型的训练过程包括监督学习和强化学习两个阶段。监督学习阶段教会模型如何感知计算机屏幕并准确点击用户界面元素,而强化学习阶段则赋予模型更高层次的能力,如推理、错误纠正和适应意外事件。
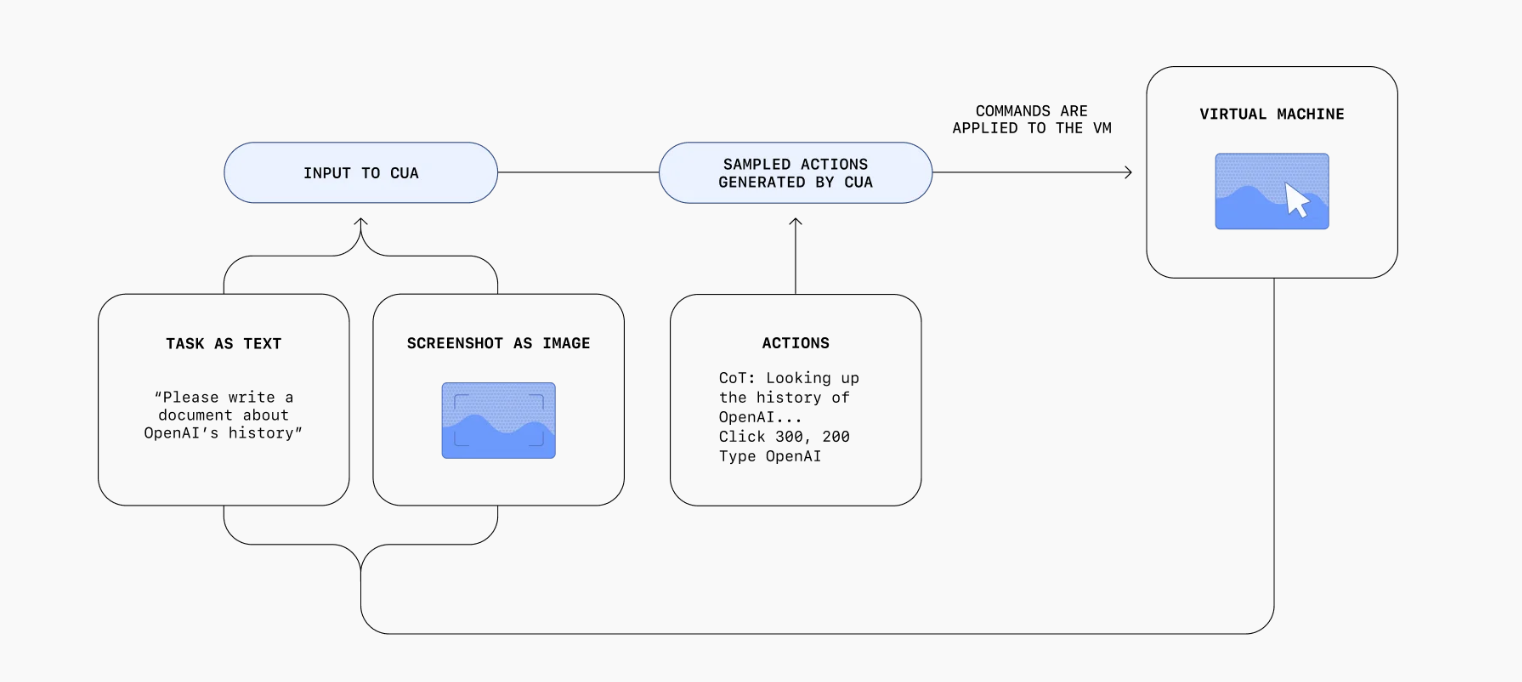
接收到用户的指令后,CUA通过一个整合了感知、推理和行动的迭代循环来操作:
- 感知:计算机的屏幕截图被添加到模型的上下文中,提供了计算机当前状态的视觉快照。
- 推理:CUA使用思考链(chain-of-thought)来推理下一步,考虑到当前和过去的屏幕截图以及动作。这种内部对话通过使模型能够评估其观察结果、跟踪中间步骤并动态适应,从而提高了任务执行的性能。
- 行动:它执行动作——点击、滚动或输入——直到它认为任务完成或需要用户输入。虽然它自动处理大多数步骤,但对于敏感操作,如输入登录详细信息或响应验证码表单,CUA会寻求用户确认。
性能测试
CUA的性能包括perception, reasoning, manipulation, long-horizon reliability, safety等方面。OpenAI分别使用OSWorld和WebArena两个benckmark评估operator agent在Computer Use和Browser Use方面的能力。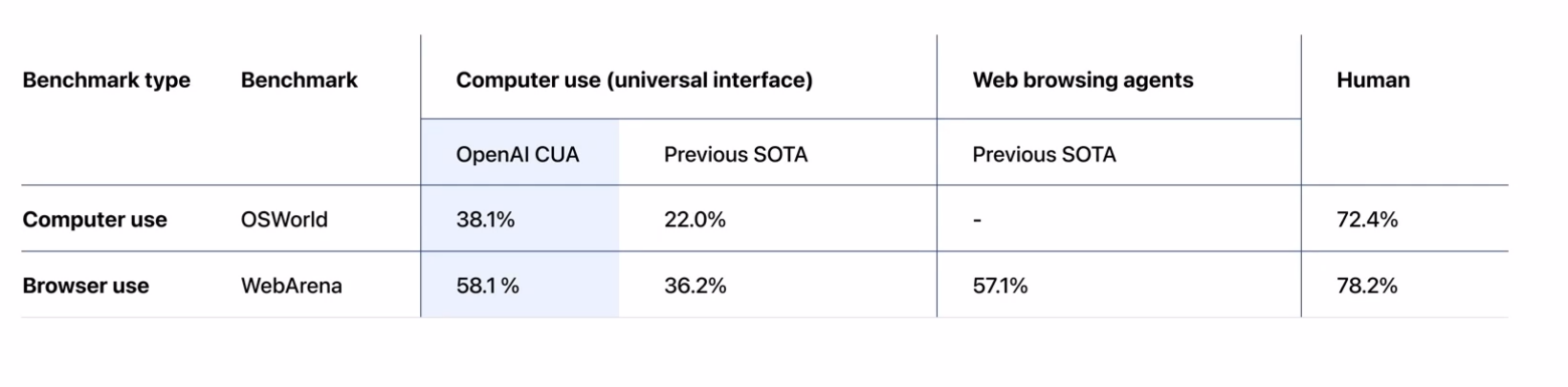
(1)OSWorld
OSWorld是一个用于评估多模态agent在真实计算机环境中执行开放式任务的基准测试集。它通过模拟各种计算机使用场景来测试agent系统的性能。OSWorld 包含总共 369 个任务(以及额外的 43 个基于 Windows 的任务用于分析)。这些任务涉及真实的计算机使用案例,并包括详细的初始状态设置配置和自定义的基于执行的评估脚本,以实现可靠和可重复的评估。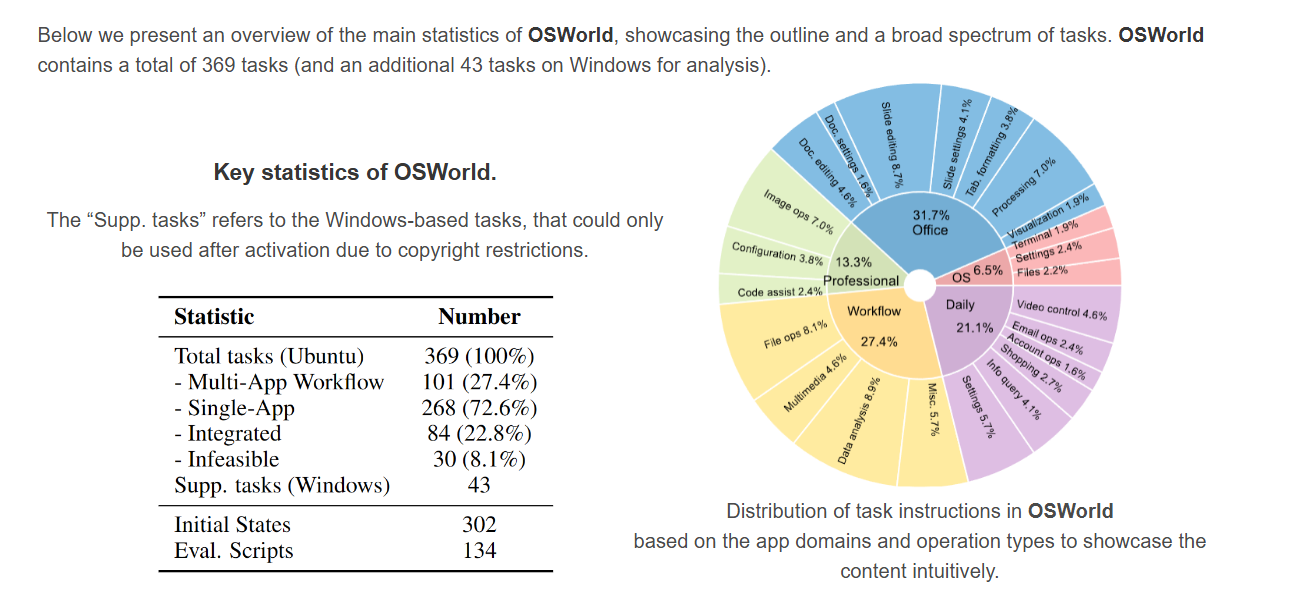
(2)WebArena
WebArena是一个用于评估agent浏览器使用性能的基准测试集。它通过模拟各种浏览器操作场景来测试agent系统的性能。
测评结果显示,在OSWorld基准测试集下,OpenAI CUA的性能为38.1%,而之前的SOTA(State of the Art,即当前最佳水平)为22.0%,人类的表现则为72.4%。
WebArena基准测试集下,OpenAI CUA的性能为58.1%,而之前的SOTA为36.2%。对于Web浏览代理,之前的SOTA为57.1%,人类的表现则为78.2%。
安全测试
CUA潜在的安全风险包括模型错误、恶意网站的提示注入攻击以及执行有害或不允许的任务。为了应对这些风险,OpenAI实施了多层次的安全措施,包括拒绝高风险任务、在关键操作前进行确认提示以及主动监控系统以检测和减轻潜在威胁。
在模型层面,Operator被训练以拒绝某些有害任务,并在内部评估中显示出对有害提示的高拒绝率。此外,系统层面的限制防止Operator导航到可能促进有害或非法活动的网站上。
Operator针对三类风险设计了不同的防范措施:
(1)第一类风险是滥用。除了要求用户遵守使用政策外,还设计了以下缓解措施来降低由于滥用导致的Operator的风险:
- 拒绝请求:CUA模型被训练以拒绝许多有害任务和非法或受监管的活动。
- 黑名单:Operator无法访问预先屏蔽的网站,例如许多赌博网站、成人娱乐网站以及毒品或枪支零售商。
- 审核:用户互动由自动化安全检查器实时审查,这些检查器旨在确保遵守使用政策,并有能力对禁止的活动发出警告或阻止。
- 离线检测:开发了自动化检测和人工审查流程,以识别优先政策领域的禁止使用情况,包括儿童安全和欺骗活动,使operator能够执行预定义的使用政策。
(2)第二类风险是模型错误,即CUA模型意外采取了用户未意图的行动,从而对用户或他人造成伤害。错误可能从轻微到严重不等,从电子邮件中的拼写错误到购买错误的商品,再到永久删除重要文件。为了最小化潜在伤害,Openai开发了以下缓解措施:
- 用户确认:CUA模型被训练在最终确定具有外部副作用的任务之前请求用户确认,例如在提交订单、发送电子邮件等之前,以便用户可以在模型的工作成为永久之前进行双重检查。
- 任务限制:目前,CUA模型将拒绝帮助执行某些高风险任务,如银行交易和需要敏感决策的任务。
- 监视模式:在特别敏感的网站,如电子邮件上,Operator需要用户的积极监督,确保用户可以直接发现并解决模型可能犯的任何潜在错误。
(3)一个特别重要的模型错误类别是针对网站进行的对抗性攻击,这些攻击导致CUA模型采取非预期行动,通过提示注入、越狱和钓鱼尝试。除了上述针对模型错误的缓解措施外,openai开发了几层额外的防御来保护这些风险:
- 谨慎导航:CUA模型被设计为识别并忽略网站上的提示注入,从早期内部红队会议中识别出的所有情况中,除了一个案例外,都能识别出来。
- 监控:在Operator中,实施了一个额外的模型来监控并在检测到屏幕上的可疑内容时暂停执行。
- 检测流程:应用了自动化检测和人工审查流程来识别可疑的访问模式,这些模式可以被标记并迅速添加到监控中(在几小时内)。
参考资料
https://x.com/OpenAI/status/1882509292659753305
https://cdn.openai.com/operator_system_card.pdf
https://openai.com/index/computer-using-agent/
https://cdn.openai.com/cua/CUA_eval_extra_information.pdf
https://os-world.github.io/
https://webarena.dev/
https://www.anthropic.com/news/3-5-models-and-computer-use

Agent 垂直技术社区,欢迎活跃、内容共建,欢迎商务合作。wx: diudiu5555
更多推荐



 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)