AGENT AI: SURVEYING THE HORIZONS OF MULTIMODAL INTERACTION (李飞飞团队智能体研究综述-中文翻译完整版本)
多模态AI系统可能会在我们的日常生活中无处不在。使这些系统更具交互性的一个有前途的方法是将它们体现为物理和虚拟环境中的代理。目前,系统利用现有的基础模型作为创建具体代理的基本构建块。在这样的环境中嵌入代理有助于模型处理和解释视觉和上下文数据的能力,这对于创建更复杂和上下文感知的AI系统至关重要。例如,可以感知用户动作、人类行为、环境对象、音频表达和场景的集体情感的系统可以用于通知和指导给定环境内的
AGENT AI: SURVEYING THE HORIZONS OF MULTIMODAL INTERACTION (李飞飞团队智能体研究综述-中文翻译完整版本)

摘要
多模态AI系统可能会在我们的日常生活中无处不在。使这些系统更具交互性的一个有前途的方法是将它们体现为物理和虚拟环境中的代理。目前,系统利用现有的基础模型作为创建具体代理的基本构建块。在这样的环境中嵌入代理有助于模型处理和解释视觉和上下文数据的能力,这对于创建更复杂和上下文感知的AI系统至关重要。例如,可以感知用户动作、人类行为、环境对象、音频表达和场景的集体情感的系统可以用于通知和指导给定环境内的代理响应。为了加速对基于代理的多模态智能的研究,我们将“代理AI”定义为一类交互式系统,可以感知视觉刺激,语言输入和其他环境接地数据,并可以产生有意义的体现行动。特别是,我们探索的系统,旨在改善代理的基础上,通过结合外部知识,多感官输入,和人类的反馈下一个具体的行动预测。我们认为,通过在接地环境中开发代理人工智能系统,还可以减轻大型基础模型的幻觉及其产生环境错误输出的倾向。Agent AI的新兴领域包含了多模式交互的更广泛的体现和代理方面。除了在物理世界中行动和交互的代理之外,我们设想了一个未来,人们可以轻松地创建任何虚拟现实或模拟场景,并与虚拟环境中体现的代理进行交互。
原文地址:AGENT AI
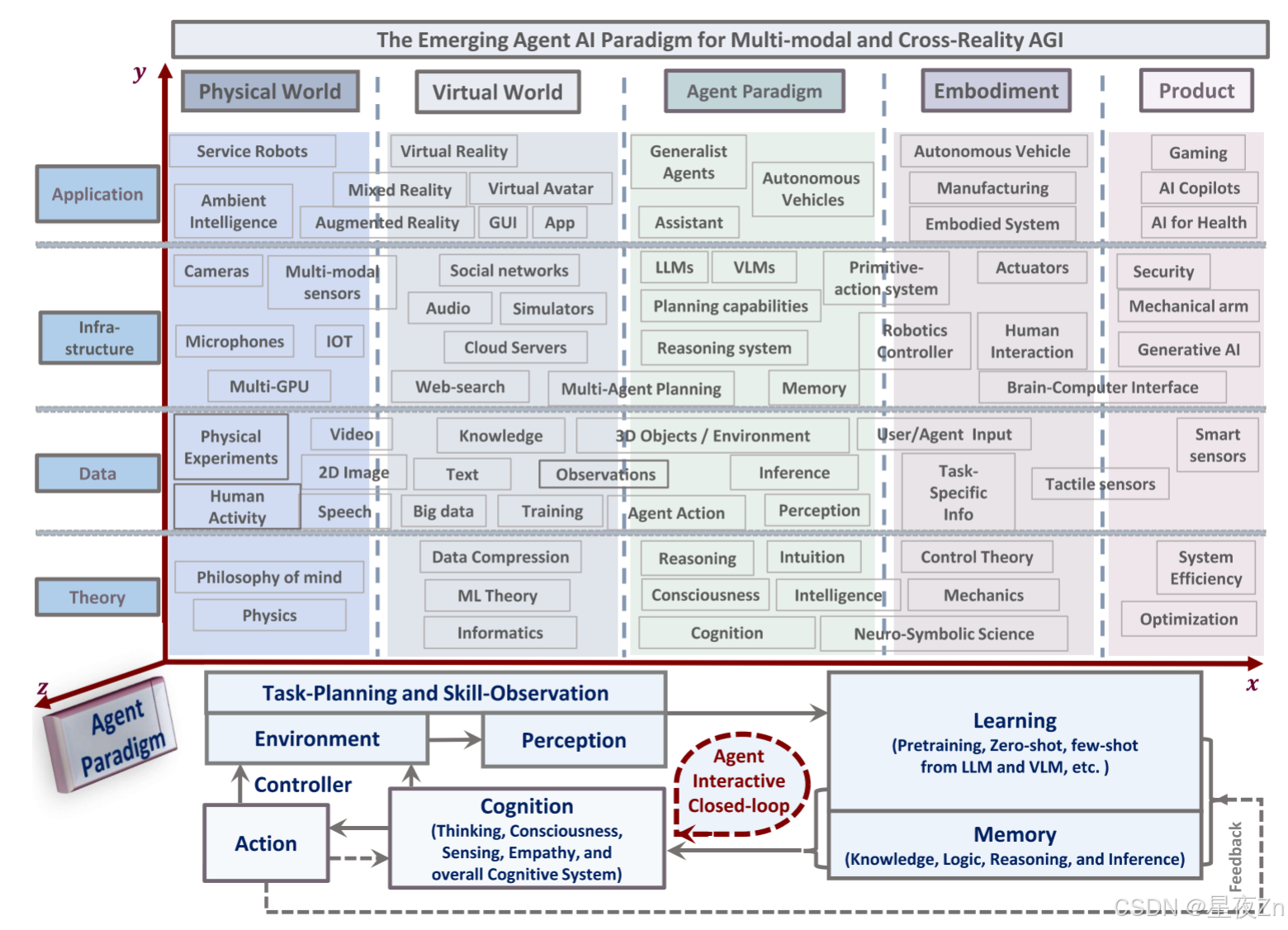
图1:可以在不同领域和应用中感知和行动的Agent AI系统概述。Agent AI正在成为实现人工通用智能(AGI)的一条有前途的途径。人工智能训练已经证明了在物理世界中进行多模态理解的能力。它通过利用生成式AI以及多个独立的数据源,为现实不可知的训练提供了一个框架。针对代理和动作相关任务训练的大型基础模型在跨现实数据上训练时可以应用于物理和虚拟世界。我们提出了一个代理人工智能系统,可以感知和行动在许多不同的领域和应用程序的一般概述,可能作为AGI使用代理范式的路线。
目录
- AGENT AI: SURVEYING THE HORIZONS OF MULTIMODAL INTERACTION (李飞飞团队智能体研究综述-中文翻译完整版本)
-
- 摘要
- 1. Introduction
- 2 Agent AI Integration
- 3 Agent AI Paradigm
- 4 Agent AI Learning
- 5 Agent AI Categorization
- 6 Agent AI Application Tasks
- 7 Agent AI Across Modalities, Domains, and Realities
- 8 Continuous and Self-improvement for Agent AI
- 9 Agent Dataset and Leaderboard
- 10 Broader Impact Statement
- 11 Ethical Considerations
- 12 Diversity Statement
1. Introduction
1.1 Motivation
从历史上看,人工智能系统在1956年的达特茅斯会议上被定义为可以从环境中收集信息并以有用的方式与之交互的人工生命形式。在这个定义的推动下,明斯基的麻省理工学院团队在1970年建立了一个机器人系统,称为“复制演示”,它观察“块世界”场景,并成功地重建了观察到的多面体块结构。该系统由观察、规划和操作模块组成,揭示了这些子问题中的每一个都具有高度的挑战性,需要进一步研究。人工智能领域被分割成多个专门的子领域,这些子领域在解决这些问题和其他问题方面基本上都取得了独立的巨大进展,但过度的简化论模糊了人工智能研究的总体目标。
要想超越现状,就必须回到亚里士多德整体论所推动的人工智能基本原理。幸运的是,最近大语言模型(LLM)和视觉语言模型(VLM)的革命使得创造符合整体理想的新型人工智能代理成为可能。本文正是抓住这一机遇,探索了整合语言能力、视觉认知、语境记忆、直觉推理和适应性的模型。它探讨了使用LLM和VLM完成这种整体综合的可能性。在我们的探索中,我们也会重新审视基于亚里士多德终极原因的系统设计,即目的论的“系统为什么存在”,这在前几轮人工智能开发中可能被忽视了。
随着强大的预训练的LLM和VLM的出现,自然语言处理和计算机视觉的复兴已经被催化。LLM现在展示了一种令人印象深刻的能力,能够解读真实世界语言数据的细微差别,通常能够达到与人类专业知识相当甚至超越人类专业知识的能力(OpenAI,2023)。最近,研究人员已经表明,LLM可以被扩展为充当各种环境中的代理,当与领域特定的知识和模块配对时执行复杂的动作和任务(Xi等人,2023年)的报告。这些场景的特征在于复杂的推理、对代理人的角色及其环境的理解沿着多步规划,这些场景测试代理人在其环境约束内做出高度细微和复杂决策的能力(Wu等人,2023年; Meta人工智能研究(FAIR)外交团队等,2022年)的报告。
在这些初步努力的基础上,人工智能社区正处于重大范式转变的风口浪尖,从为被动的结构化任务创建人工智能模型过渡到能够在多样化和复杂环境中承担动态代理角色的模型。在此背景下,本文探讨了将语言学习模型和语言学习模型作为智能体的巨大潜力,强调了融合了语言熟练度、视觉认知、上下文记忆、直觉推理和适应性的模型。利用LLM和VLM作为代理,特别是在游戏、机器人和医疗保健等领域,不仅可以为最先进的人工智能系统提供严格的评估平台,还预示着以代理为中心的人工智能将在社会和行业中产生变革性影响。当被充分利用时,代理模型可以重新定义人类体验并提升运营标准。这些模式带来的全面自动化的潜力预示着行业和社会经济动态的巨大变化。这些进步将与多方面的领导者委员会交织在一起,不仅是技术上的,也是道德上的,我们将在第11节中详细阐述。我们深入研究了Agent AI的这些子领域的重叠区域,并在图1中说明了它们的相互关联性。
1.2 Background
现在我们将介绍支持Agent AI的概念、理论背景和现代实现的相关研究论文。
大型基础模型:LLM和VLM一直在推动开发通用智能机器的努力(Bubeck等人,2023年; Mirchandani等人,2023年)的报告。虽然他们是使用大型文本语料库进行训练的,但他们上级的问题解决能力并不局限于规范语言处理领域。LLM可以潜在地处理复杂的任务,这些任务以前被认为是人类专家或特定领域算法所专有的,其范围从数学推理(Imani等人,2023年; Wei等人,2022年; Zhu等人,2022年)到回答专业法律问题(Blair-Stanek等人,2023年; Choi等人,2023年;不,2022年)。最近的研究已经显示了使用LLM来生成用于机器人和游戏AI的复杂计划的可能性(Liang等人,2022; Wang等人,2023 a,B; Yao等人,2023 a; Huang等人,2023 a),标志着LLM作为通用智能代理的重要里程碑。
具身化AI:许多工作利用LLM来执行任务规划(Huang等人,2022 a; Wang等人,2023 b; Yao等人,2023 a; Li等人,2023 a),具体而言,LLM的WWW尺度领域知识和突现零触发体现了执行复杂任务规划和推理的能力。最近的机器人研究还利用LLM来执行任务规划(Ahn等人,2022 a; Huang等,2022 b; Liang等,2022),通过将自然语言指令分解成自然语言形式或Python代码的子任务序列,然后使用低级控制器来执行这些子任务。此外,它们结合了环境反馈以改善任务表现(Huang等人,2022 b),(Liang等人,2022),(Wang等人,2023 a),以及(Ikeuchi等人,2023年)的报告。
交互式学习:为交互式学习而设计的人工智能代理使用机器学习技术和用户交互的组合进行操作。最初,人工智能代理在大型数据集上进行训练。该数据集包括各种类型的信息,具体取决于代理的预期功能。例如,一个为语言任务设计的人工智能将在大量文本数据的语料库上进行训练。培训涉及使用机器学习算法,其中可能包括神经网络等深度学习模型。这些训练模型使人工智能能够识别模式、做出预测,并根据训练数据生成响应。人工智能代理还可以从与用户的实时交互中学习。这种交互式学习可以以各种方式发生:1)基于反馈的学习:AI基于直接用户反馈来调整其响应(Li等人,2023 b; Yu等人,2023 a; Parakh等人,2023年;查等人,2023年; Wake等人,2023年a、B、c)。例如,如果用户校正了AI的响应,则AI可以使用该信息来改进将来的响应(Zha等人,2023; Liu等人,第2023条a款)。2)观察式学习:人工智能观察用户交互并进行隐式学习。例如,如果用户频繁地提出类似的问题或以特定的方式与AI交互,AI可能会调整其响应以更好地适应这些模式。它允许人工智能主体理解和处理人类语言、多模型设置、解释跨现实上下文以及生成人类用户的响应。随着时间的推移,随着更多的用户交互和反馈,AI代理的性能通常会不断提高。这一过程通常由人类操作员或开发人员监督,他们确保AI正在适当地学习,而不会产生偏见或错误的模式。
1.3 Overview
多模态智能体AI(MAA)是一系列系统,它们基于对多模态感官输入的理解,在给定环境中生成有效的动作。随着大语言模型(LLM)和视觉语言模型(VLM)的出现,从基础研究到应用领域都提出了许多MAA系统。虽然这些研究领域通过与每个领域的传统技术(例如,视觉问答和视觉语言导航),他们有着共同的兴趣,如数据收集,基准测试和道德观点。在本文中,我们专注于MAA的一些代表性研究领域,即多模态,游戏(VR/AR/MR),机器人和医疗保健,我们的目标是提供这些领域中讨论的共同关注的全面知识。因此,我们希望了解MAA的基本原理,并获得进一步推进研究的见解。具体的学习成果包括:
- MAA概述:深入研究其原理和在当代应用中的作用,为研究人员提供对其重要性和用途的全面掌握。
- 方法论:LLM和VLM如何增强MAA的详细示例,通过游戏,机器人和医疗保健的案例研究进行说明。
- 绩效评估:关于使用相关数据集评估MAA的指导,重点是其有效性和普遍性。 道德考量:讨论部署Agent
- AI的社会影响和道德领导委员会,强调负责任的开发实践。
- 新兴趋势和未来排行榜:对每个领域的最新发展进行分类,并讨论未来的发展方向。
基于计算机的行动和通才代理(GAs)对许多任务都很有用。一个GA要想对用户真正有价值,它可以很自然地与之交互,并推广到广泛的上下文和模式。我们的目标是培养一个充满活力的研究生态系统,并在Agent AI社区中创造一种共同的认同感和目的感。MAA有可能广泛适用于各种背景和模式,包括人类的输入。因此,我们相信这个人工智能领域可以吸引各种各样的研究人员,培养一个充满活力的人工智能社区和共同的目标。在学术界和工业界受人尊敬的专家的带领下,我们希望本文将是一次互动和丰富的体验,包括代理人指导、案例研究、任务会议和实验讨论,确保所有研究人员都能获得全面和引人入胜的学习体验。
本文旨在对Agent人工智能领域的研究现状提供一个较为全面的认识。为此,本文其余部分的组织结构如下。第2节概述了Agent AI如何从与相关新兴技术(尤其是大型基础模型)的集成中获益。第3节描述了我们提出的用于训练Agent AI的新的范式和框架。第4节概述了Agent AI训练中广泛使用的方法。第5节对各种类型的代理进行了分类和讨论。第6节介绍Agent AI在游戏、机器人和医疗保健领域的应用。第7节探讨了研究界为开发一个多功能的Agent AI所做的努力,该Agent AI能够应用于各种模式、领域,并弥合模拟到真实的差距。第8节讨论了Agent AI的潜力,它不仅依赖于预先训练的基础模型,而且还通过利用与环境和用户的交互不断学习和自我改进。第9节介绍了我们为训练多模态Agent AI而设计的新数据集。第11节讨论了人工智能主体的伦理考量、局限性以及本文的社会影响等热点话题。
2 Agent AI Integration
如先前研究中所提出的,基于LLM和VLM的基础模型在具体化AI领域中仍然表现出有限的性能,特别是在不可见环境或场景中的理解、生成、编辑和交互方面(Huang等人,2023 a; Zeng等人,2023年)的报告。因此,这些限制导致AI代理的次优输出。当前的以主体为中心的AI建模方法关注于可直接访问和明确定义的数据(例如,世界状态的文本或字符串表示),并且通常使用从其大规模预训练中学习到的与领域和环境无关的模式来预测每个环境的动作输出(Xi等人,2023; Wang等人,2023 c; Gong等人,2023 a; Wu等人,2023年)的报告。在(Huang等人,2023 a),我们研究了通过组合大型基础模型的知识引导的协作和交互式场景生成的任务,并且显示了有希望的结果,该结果表明基于知识的LLM代理可以提高2D和3D场景理解、生成和编辑以及其他人-代理交互的性能(Huang等人,第2023条a款)。通过集成Agent AI框架,大型基础模型能够更深入地理解用户输入,形成复杂的自适应人机交互系统。LLM和VLM的突现能力在生成式AI、具身AI、用于多模型学习的知识扩充、混合现实生成、文本到视觉编辑、用于游戏或机器人任务中的2D/3D模拟的人类交互中不可见。智能体人工智能在基础模型方面的最新进展为在实体化智能体中解锁一般智能提供了一种迫在眉睫的催化剂。大型动作模型或主体-视觉-语言模型为通用的具体化系统(如复杂环境中的规划、问题解决和学习)开辟了新的可能性。Agent AI在metaverse中测试进一步的步骤,并路由早期版本的AGI。
2.1 Infinite AI agent
人工智能代理具有解释、预测和基于其训练和输入数据做出响应的能力。虽然这些能力是先进的,并在不断改进,但重要的是要认识到它们的局限性和它们所训练的基础数据的影响。人工智能代理系统通常具有以下能力:1)预测建模:人工智能代理可以预测可能的结果,或根据历史数据和趋势建议下一步。例如,它们可以预测文本的延续、问题的答案、机器人的下一个动作或场景的解决方案。2)决策:在一些应用中,人工智能代理可以根据自己的推断做出决策。通常,代理人会根据最有可能实现指定目标的方式来做出决策。对于推荐系统等AI应用,代理可以根据其对用户偏好的推断来决定推荐什么产品或内容。3)处理歧义:人工智能代理通常可以通过基于上下文和训练推断最可能的解释来处理歧义输入。但是,它们这样做的能力受到它们的训练数据和算法的范围的限制。4)持续改进:虽然一些人工智能代理有能力从新的数据和交互中学习,但许多大型语言模型在训练后不会持续更新它们的知识库或内部表示。他们的推断通常仅基于截至其上次训练更新时可用的数据。
我们在图2中展示了用于多通道和跨现实不可知集成的增强型交互代理,以及一种涌现机制。人工智能代理需要为每个新任务收集大量的训练数据,这对许多领域来说可能是昂贵的或不可能的。在这项研究中,我们开发了一个无限代理,它学习将记忆信息从一般的基础模型(如GPT-X,DALL-E)传输到新的域或场景,用于在物理或虚拟世界中理解、生成和交互编辑场景。这种无限代理在机器人学中的一个应用是RoboGen(Wang等人,2023d)。在这项研究中,作者提出了一条自动运行任务命题、环境生成和技能学习循环的管道。RoboGen是一项将大型模型中嵌入的知识转移到机器人领域的努力。
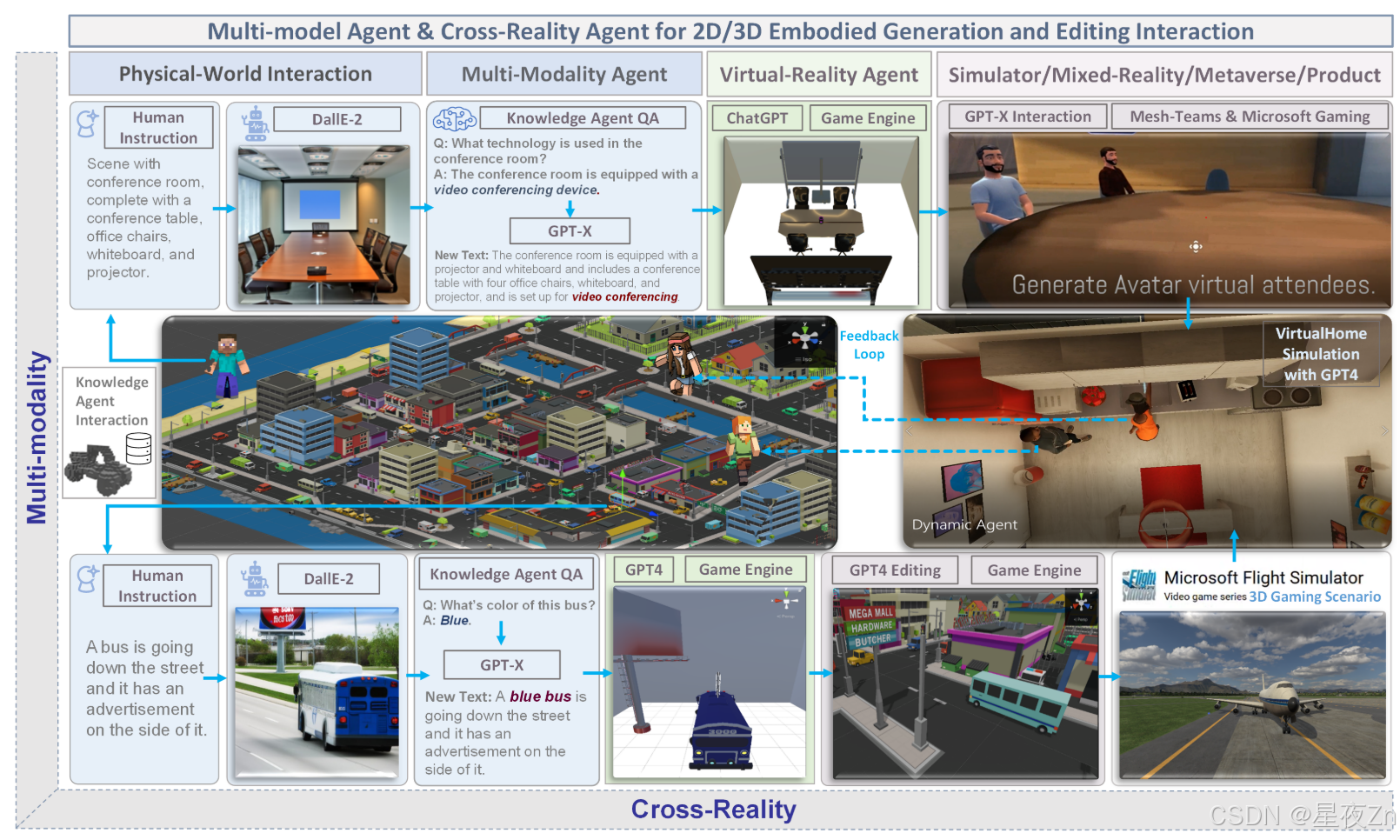
图2:面向2D/3D的多模型智能体AI体现了跨现实的生成和编辑交互。
2.2 Agent AI with Large Foundation Models
最近的研究表明,大型基础模型在创建数据方面发挥着至关重要的作用,这些数据作为基准,用于确定在环境施加的约束条件下主体的行动。例如,使用用于机器人操纵的基础模型(Black等人,2023年; Ko等人,2023)和导航(Shah等人,2023 a; Zhou等人,第2023条a款)。为了说明,Black等人采用了一种图像编辑模型作为高级计划者,以生成未来子目标的图像,从而指导低级政策(Black等人,2023年)的报告。对于机器人导航,Shah等人提出了一种系统,该系统采用LLM来从文本中识别界标,并采用VLM来将这些界标与视觉输入相关联,从而增强了通过自然语言指令的导航(Shah等人,第2023条a款)。人们也越来越感兴趣的是产生条件化的人类动作,以响应语言和环境因素。已经提出了几种AI系统来生成适合于特定语言指令的运动和动作(Kim等人,2023; Zhang等人,2022年; Tevet等人,2022)并适应于各种3D场景(Wang等人,第2022条a款)。这一研究机构强调了生成模型在增强AI代理跨不同场景的适应性和响应性方面不断增长的能力。
2.2.1 Hallucinations
生成文本的代理经常倾向于产生幻觉,这是生成的文本是无意义的或与提供的源内容不忠实的情况(Raunak等人,2021年; Maynez等人,2020年)的报告。幻觉可以分为两类,内在的和外在的(Ji等人,2023年)的报告。内在幻觉是与原始材料相矛盾的幻觉,而外在幻觉是当生成的文本包含原始材料中最初没有包含的额外信息时。
在语言生成中降低幻觉率的一些有希望的途径包括使用检索增强生成(刘易斯等人,2020年; Shuster等人,2021)或用于经由外部知识检索来为自然语言输出奠定基础的其它方法(Dziri等人,2021年; Peng等人,2023年)的报告。通常,这些方法通过检索附加的源材料并通过提供检查所生成的响应与源材料之间的矛盾的机制来寻求增强语言生成。在多模式试剂系统的背景下,VLM也显示出幻觉(Zhou等人,第2023段b)。对于基于视觉的语言生成产生幻觉的一个常见原因是由于过度依赖于训练数据中物体和视觉线索的同时出现(Rohrbach等人,(2018年版)。完全依赖于预先训练的LLM或VLM并使用有限的环境特定微调的AI代理可能特别容易受到幻觉的影响,因为它们依赖于预先训练的模型的内部知识库来生成动作,并且可能无法准确地理解它们所部署的世界状态的动态。
2.2.2 Biases and Inclusivity
基于LLM或LLM(大型多模态模型)的AI代理由于其设计和训练过程中固有的几个因素而存在偏差。在设计这些人工智能代理时,我们必须注意包容性,并意识到所有最终用户和利益相关者的需求。在人工智能代理的背景下,包容性是指用于确保代理的响应和交互对来自不同背景的广泛用户具有包容性、尊重性和敏感性的措施和原则。我们在下面列出了代理人偏见和包容性的关键方面。
- 培训数据:基金会模型是在从互联网上收集的大量文本数据上训练的,包括书籍、文章、网站和其他文本来源。这些数据通常反映了人类社会中存在的偏见,而模型可以在无意中学习和重现这些偏见。这包括与种族、性别、民族、宗教和其他个人属性有关的成见、偏见和偏见。特别是,通过对互联网数据和通常只有英语文本的训练,模型隐含地学习西方教育化、工业化、富裕和民主(WEIRD)社会的文化规范(Henrich等人,2010年),在互联网上拥有不成比例的庞大存在。然而,必须认识到,人类创建的数据集不可能完全没有偏见,因为它们经常反映出社会偏见和最初生成和/或汇编数据的个人的倾向。
- 历史和文化偏见:人工智能模型是在来自不同内容的大型数据集上训练的。因此,训练数据通常包括来自各种文化的历史文本或材料。特别是,来自历史来源的培训数据可能包含代表特定社会文化规范、态度和偏见的冒犯性或贬损性语言。这可能导致模式延续过时的陈规定型观念,或不充分理解当代文化的变化和细微差别。
- 语言和上下文限制:语言模型可能难以理解和准确表示语言中的细微差别,例如讽刺、幽默或文化引用。在某些情况下,这可能会导致误解或有偏见的反应。此外,口语的许多方面无法通过纯文本数据捕获,导致人类对语言的理解与模型如何理解语言之间存在潜在的脱节。
- 政策和准则:人工智能代理在严格的政策和准则下运作,以确保公平性和包容性。例如,在生成图像时,有一些规则可以使人们的偏好多样化,避免与种族,性别和其他属性有关的刻板印象。
- 过度泛化:这些模型倾向于根据训练数据中看到的模式生成响应。这可能会导致过度概括,模型可能会产生似乎刻板印象或对某些群体做出广泛假设的反应。
- 持续监控和更新:人工智能系统持续监控和更新,以解决任何新出现的偏见或包容性问题。来自用户的反馈和正在进行的人工智能伦理研究在这一过程中发挥着至关重要的作用。
- 扩大主导观点:由于训练数据通常包含更多来自主流文化或群体的内容,因此模型可能更偏向于这些观点,可能会低估或歪曲少数群体的观点。
- 道德和包容性设计:人工智能工具的设计应将道德考虑和包容性作为核心原则。这包括尊重文化差异,促进多样性,并确保大赦国际不使有害的陈规定型观念永久化。
- 用户指南:用户还将获得如何以促进包容性和尊重的方式与AI互动的指导。这包括避免提出可能导致有偏见或不适当产出的要求。此外,它还可以帮助减少模型从用户交互中学习有害内容的情况。
尽管有这些措施,人工智能代理仍然表现出偏见。智能体人工智能研发的持续努力集中在进一步减少这些偏见,增强智能体人工智能系统的包容性和公平性。减轻偏倚的努力:
- 多样化和包容性的培训数据:努力在培训数据中纳入更多样化和包容性的来源。
- 偏差检测和纠正:正在进行的研究侧重于检测和纠正模型响应中的偏差。
- 道德准则和政策:模型通常受道德准则和政策的约束,旨在减少偏见,确保相互尊重和包容的互动。
- 多样性表现:确保人工智能代理生成的内容或提供的响应能够代表广泛的人类经验、文化、种族和身份。这一点在图像生成或叙事构建等场景中尤为重要。
- 偏差缓解:积极减少人工智能响应中的偏差。这包括与种族、性别、年龄、残疾、性取向和其他个人特征相关的偏见。其目标是提供公平和平衡的反应,不使陈规定型观念或偏见永久化。
- 文化敏感性:《大赦国际》旨在对文化敏感,承认和尊重文化规范、做法和价值观的多样性。这包括理解和适当地应对文化参照和细微差别。
- 可访问性:确保AI代理可供不同能力的用户访问,包括残疾用户。这可能涉及到加入一些功能,使视觉、听觉、运动或认知障碍的人更容易进行互动。
- 基于语言的包容性:提供对多种语言和方言的支持,以迎合全球用户群的需求,并对语言中的细微差别和变化保持敏感(Liu等人,第2023段b)。
- 道德和尊重的互动:代理程序被编程为以道德和尊重的方式与所有用户互动,避免可能被视为冒犯、有害或不尊重的响应。
- 用户反馈和自适应:收集用户反馈,以不断提高AI代理的包容性和有效性。这包括从互动中学习,以更好地理解和服务于多样化的用户群。
- 遵守包容性准则:遵守人工智能代理人包容性的既定准则和标准,这些准则和标准通常由行业团体、伦理委员会或监管机构制定。
尽管做出了这些努力,但重要的是要意识到反应中可能存在的偏见,并用批判性思维来解释它们。人工智能代理技术和道德实践的持续改进旨在随着时间的推移减少这些偏见。智能体人工智能包容性的首要目标之一是创建一个尊重所有用户且可访问的智能体,无论其背景或身份如何。
2.2.3 Data Privacy and Usage
人工智能代理的一个关键道德考虑因素涉及理解这些系统如何处理,存储和潜在地检索用户数据。我们讨论以下关键方面:
数据的收集、使用和目的。当使用用户数据来提高模型性能时,模型开发人员会访问AI代理在生产过程中以及与用户交互时收集的数据。某些系统允许用户通过用户帐户或通过向服务提供商提出请求来查看其数据。识别AI代理在这些交互过程中收集的数据非常重要。这可能包括文本输入、用户使用模式、个人偏好,有时还包括更敏感的个人信息。用户还应了解如何使用从其交互中收集的数据。如果由于某种原因,人工智能持有关于特定个人或团体的错误信息,则应建立一种机制,让用户在发现后帮助纠正这一错误。这对于准确性和尊重所有用户和组都很重要。检索和分析用户数据的常见用途包括改进用户交互、个性化响应和系统优化。对于开发人员来说,确保数据不被用于用户未同意的目的(如未经请求的营销)是极其重要的。
存储和安全性。开发人员应该知道用户交互数据的存储位置,以及采取了哪些安全措施来保护数据免受未经授权的访问或破坏。这包括加密、安全服务器和数据保护协议。确定是否与第三方共享座席数据以及在何种条件下共享座席数据是极其重要的。这应该是透明的,通常需要用户同意。
数据删除和保留。对于用户来说,了解用户数据的存储时间以及用户如何请求删除这些数据也很重要。许多数据保护法赋予用户被遗忘的权利,这意味着他们可以要求擦除他们的数据。人工智能代理必须遵守欧盟的GDPR或加州的CCPA等数据保护法。这些法律适用于数据处理实践和用户关于其个人数据的权利。
数据可移植性和隐私政策。此外,开发人员必须创建AI代理的隐私策略,以记录并向用户解释如何处理他们的数据。其中应详细说明数据收集、使用、存储和用户权限。开发人员应确保在收集数据(尤其是敏感信息)时获得用户的同意。用户通常可以选择退出或限制他们提供的数据。在某些司法管辖区,用户甚至有权要求以可传输给其他服务提供商的格式提供其数据的副本。
匿名化。对于在更广泛的分析或AI培训中使用的数据,理想情况下应该匿名,以保护个人身份。开发人员必须了解他们的AI代理在交互过程中如何检索和使用历史用户数据。这可能是为了个性化或提高响应相关性。
总而言之,理解AI代理的数据隐私包括了解用户数据是如何被收集、使用、存储和保护的,并确保用户了解他们在访问、更正和删除数据方面的权利。用户和人工智能代理对数据检索机制的了解对于全面理解数据隐私也至关重要。
2.2.4 Interpretability and Explainability
模仿学习→解耦。代理通常使用强化学习(RL)或模仿学习(IL)中的连续反馈循环进行训练,从随机初始化的策略开始。然而,这种方法在不熟悉的环境中获得初始奖励时面临排行榜,特别是当奖励稀疏或仅在长步骤交互结束时可用时。因此,一个上级解决方案是使用通过IL训练的无限内存代理,它可以从专家数据中学习策略,改善对具有新兴基础设施的不可见环境空间的探索和利用,如图3所示。具有专家特性,帮助智能体更好地探索和利用看不见的环境空间。Agent AI可以直接从专家数据中学习策略和新的范式流。
传统的IL有一个代理模仿专家演示者的行为来学习策略。然而,直接学习专家策略可能并不总是最好的方法,因为智能体可能无法很好地推广到看不见的情况。为了解决这个问题,我们建议学习一个带有上下文提示或隐式奖励函数的代理,它可以捕获专家行为的关键方面,如图3所示。这为无限内存代理提供了从专家演示中学习到的用于任务执行的物理世界行为数据。它有助于克服现有的模仿学习缺点,例如需要大量专家数据和复杂任务中的潜在错误。Agent AI背后的关键思想有两个部分:1)收集物理世界专家演示作为状态-动作对的无限代理,以及2)模仿代理生成器的虚拟环境。模仿代理产生模仿专家的行为的动作,而代理通过减少专家的动作和由学习的策略生成的动作之间的差异的损失函数来学习从状态到动作的策略映射。
解耦→泛化。代理不依赖于特定于任务的奖励函数,而是从专家演示中学习,专家演示提供了一组涵盖各种任务方面的状态-动作对。然后,代理通过模仿专家的行为来学习将状态映射到动作的策略。模仿学习中的解耦是指将学习过程与特定任务的奖励函数分离,允许策略在不同任务之间泛化,而不显式依赖特定任务的奖励函数。通过解耦,代理可以从专家演示中学习,并学习适应各种情况的策略。解耦使迁移学习成为可能,在一个领域中学习的策略可以以最小的微调适应其他领域。通过学习不与特定奖励函数绑定的一般策略,智能体可以利用它在一个任务中获得的知识在其他相关任务中表现良好。由于智能体不依赖于特定的奖励函数,因此它可以适应奖励函数或环境的变化,而无需进行大量的重新训练。这使得学习的策略在不同的环境中更加健壮和通用。解耦是指在学习过程中分离两个任务:学习奖励函数和学习最优策略。
概括→涌现行为。泛化解释了如何从更简单的组件或规则中产生紧急属性或行为。关键思想在于识别控制系统行为的基本元素或规则,例如单个神经元或基本算法。因此,通过观察这些简单的组件或规则如何相互作用。这些组件的相互作用往往会导致复杂行为的出现,而这些行为是无法通过单独检查单个组件来预测的。跨不同复杂性级别的泛化允许系统学习适用于这些级别的一般原则,从而产生紧急属性。这使系统能够适应新的情况,展示更复杂的行为从简单的规则中出现。此外,跨不同复杂性水平进行概括的能力有助于知识从一个领域转移到另一个领域,这有助于随着系统的适应,在新的环境中出现复杂的行为。

图3:紧急交互机制的示例,使用代理从候选人中识别与图像相关的文本。该任务涉及使用来自网络的多模态AI代理和人类注释的知识交互样本来整合外部世界信息。
2.2.5 Inference Augmentation
人工智能代理的推理能力在于它根据训练和输入数据解释,预测和响应的能力。虽然这些能力是先进的,并在不断改进,但重要的是要认识到它们的局限性和它们所训练的基础数据的影响。特别是在大型语言模型的背景下,它指的是根据它所训练的数据和接收的输入得出结论,做出预测和生成响应的能力。AI代理中的推理增强是指通过额外的工具,技术或数据来增强AI的自然推理能力,以提高其性能,准确性和实用性。这在复杂的决策场景中或处理细微差别或专业内容时尤为重要。我们在下面表示了推理增强的特别重要的来源:
数据丰富。整合额外的(通常是外部的)数据源以提供更多的上下文或背景,可以帮助AI代理做出更明智的推断,尤其是在其训练数据可能有限的领域。例如,人工智能代理可以从对话或文本的上下文中推断出意思。他们分析给定的信息,并使用它来理解用户查询的意图和相关详细信息。这些模型在识别数据模式方面非常熟练。他们利用这种能力,根据他们在培训中学到的模式,对语言、用户行为或其他相关现象进行推断。
算法增强。改进人工智能的底层算法,以做出更好的推断。这可能涉及使用更先进的机器学习模型,集成不同类型的AI(如将NLP与图像识别相结合),或更新算法以更好地处理复杂任务。语言模型中的推理涉及理解和生成人类语言。这包括把握语调、意图等细微差别,以及不同语言结构的微妙之处。
人在回路(HITL)。在人类判断至关重要的领域,例如道德考量、创造性任务或模棱两可的场景,引入人类输入来增强人工智能的推理尤其有用。人类可以提供指导,纠正错误,或者提供代理人自己无法推断的见解。
实时反馈集成。使用来自用户或环境的实时反馈来增强推理是另一种用于在推理期间改进性能的有前途的方法。例如,AI可能会根据实时用户响应或动态系统中不断变化的条件来调整其推荐。或者,如果代理在模拟环境中采取了违反某些规则的操作,则可以动态地向代理提供反馈以帮助其自我纠正。
跨领域知识传授。利用一个领域的知识或模型来改进另一个领域的推理在专业领域内产生输出时尤其有用。例如,为语言翻译开发的技术可能会应用于代码生成,或者来自医疗诊断的见解可以增强机器的预测性维护。
针对特定使用情形的定制。为特定应用或行业量身定制AI的推理能力可能涉及到在专门的数据集上训练AI或微调其模型以更好地适应特定任务,如法律的分析、医疗诊断或金融预测。由于一个域内的特定语言或信息可以与来自其它域的语言形成很大的对比,因此在域特定信息上微调代理是有益的。
伦理和偏见考虑。重要的是要确保扩增过程不会引入新的偏见或道德问题。这涉及到仔细考虑额外数据的来源或新的推理增强算法对公平性和透明度的影响。在做出推论时,特别是在敏感话题上,人工智能代理有时必须考虑到道德因素。这包括避免有害的陈规定型观念、尊重隐私和确保公平。
持续学习和适应。定期更新和完善人工智能的功能,以跟上新的发展、不断变化的数据环境和不断变化的用户需求。
总之,人工智能智能体中的推理增强涉及到通过附加数据、改进算法、人工输入和其他技术来增强其自然推理能力的方法。根据用例的不同,这种增强对于处理复杂任务和确保代理输出的准确性通常是必要的。
2.2.6 Regulation
最近,Agent AI取得了重大进展,它与具体系统的集成为通过更具沉浸式,动态和吸引力的体验与代理进行交互开辟了新的可能性。为了加快这一过程并减轻Agent AI开发中的繁琐工作,我们建议为Agent交互开发下一代AI授权管道。开发一个人机协作系统,人类和机器可以进行有意义的交流和互动。该系统可以利用LLM或VLM对话功能和大量动作来与人类玩家交谈并识别人类需求。然后,它将根据请求执行适当的操作以帮助人类玩家。
当将LLM/VLM用于人机协作系统时,必须注意这些操作是黑盒,会产生不可预测的输出。这种不确定性在物理设置中可能变得至关重要,例如操作实际的机器人。解决这一挑战的一种方法是通过及时的工程来约束LLM/VLM的重点。例如,在根据指令进行机器人任务规划时,据报道,在提示中提供环境信息比仅依赖文本产生更稳定的输出(Gramopadhye和Szafir,2022)。这份报告是由明斯基的人工智能框架理论(明斯基,1975年),建议LLM/VLMs解决的问题空间是由给定的提示定义的支持。另一种方法是设计提示,使LLM/VLM包括解释性文本,以允许用户理解模型关注或识别的内容。此外,实现一个允许在人工指导下进行预执行验证和修改的更高层,可以简化在这种指导下工作的系统的操作(图4)。
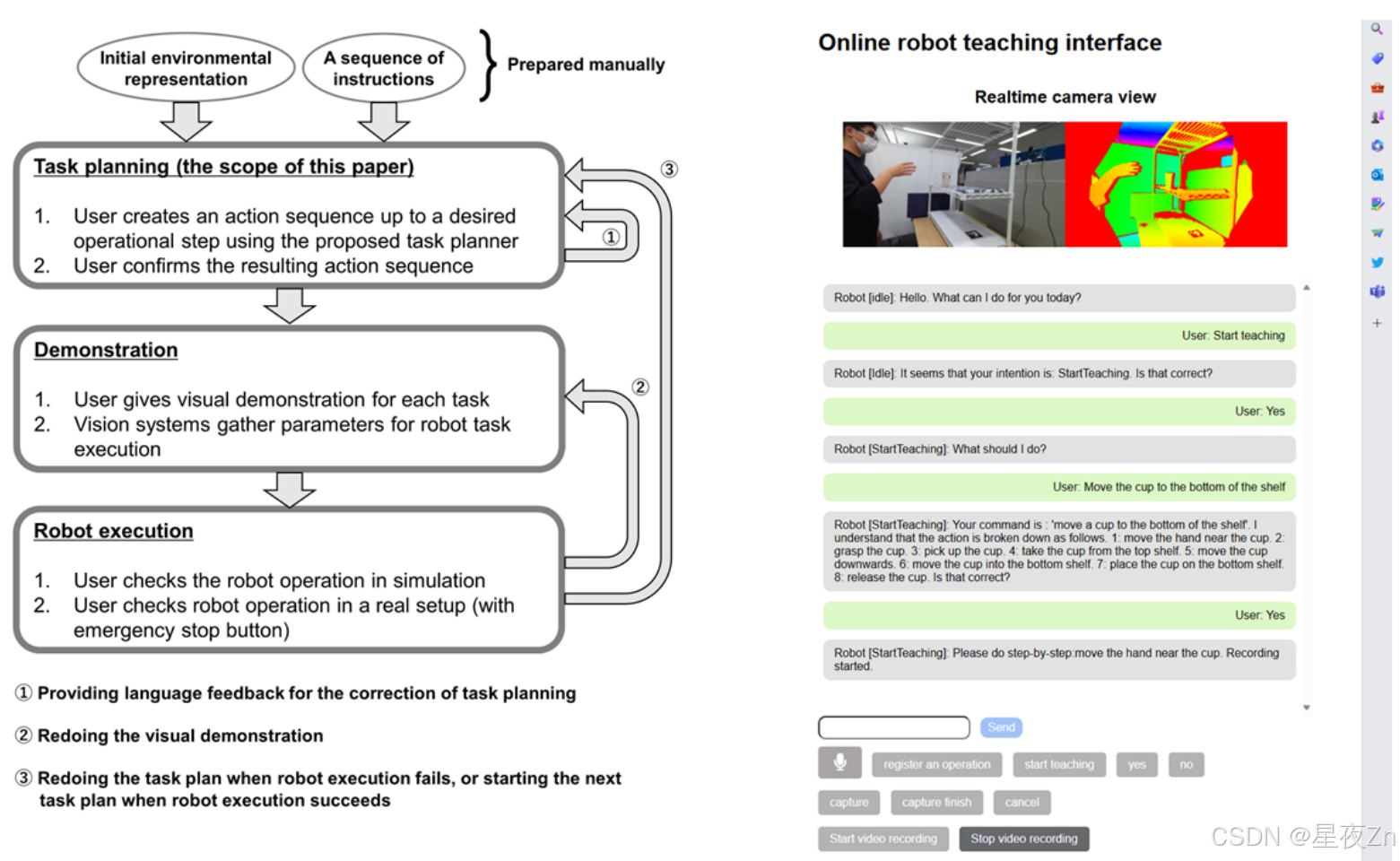
图4:在(Wake等人,第2023条c款)。(左)系统工作流程。该过程包括三个步骤:任务规划,ChatGPT根据指令和环境信息规划机器人任务;演示,用户直观地演示动作序列。所有步骤都由用户进行检查,如果任何步骤失败或显示出缺陷,则可以根据需要重新访问之前的步骤。(右)一个Web应用程序,可用于上传演示数据以及用户与ChatGPT之间的交互。
2.3 Agent AI for Emergent Abilities
尽管越来越多地采用交互式代理人工智能系统,但大多数提出的方法在看不见的环境或场景中的泛化性能方面仍然面临挑战。当前的建模实践要求开发人员为每个领域准备大型数据集,以微调/预训练模型;然而,如果领域是新的,则此过程成本高昂,甚至是不可能的。为了解决这个问题,我们构建了交互式代理,利用通用基础模型(ChatGPT、Dall-E、GPT-4等)的知识记忆。用于一种新颖的场景,特别是用于生成人与代理之间的协作空间。我们发现了一种新兴的机制-我们将其命名为混合现实与知识推理交互-促进与人类的合作,以解决复杂的现实环境中具有挑战性的任务,并使探索看不见的环境适应虚拟现实。对于这种机制,智能体学习i)跨模态中的微反应:收集每个交互任务的相关个体知识(例如,理解看不见的场景)从显式的网络源,并通过从预训练模型的输出隐式推断; ii)现实不可知的宏观行为:改善语言和多模态领域的交互维度和模式,并根据特征化角色,某些目标变量,混合现实和LLM中协作信息的影响多样化进行更改。我们研究了知识引导的交互协同效应的任务,以协同场景生成与各种OpenAI模型相结合,并展示了交互式代理系统如何进一步提升我们设置中的大型基础模型的有希望的结果。它集成并提高了复杂自适应人工智能系统的泛化、意识和可解释性的深度。
3 Agent AI Paradigm
在本节中,我们将讨论一种用于训练Agent AI的新范式和框架。
- 利用现有的预训练模型和预训练策略,有效地引导我们的智能体有效地理解重要的模态,如文本或视觉输入。
- 支持足够的长期任务规划能力。
- 建立一个记忆框架,以便对学习到的知识进行编码,并在以后检索。
- 允许利用环境反馈有效地培训代理人,使其学会采取哪些行动。
在图5中,我们展示了一个高级的新代理图,它概括了这样一个系统的重要子模块。
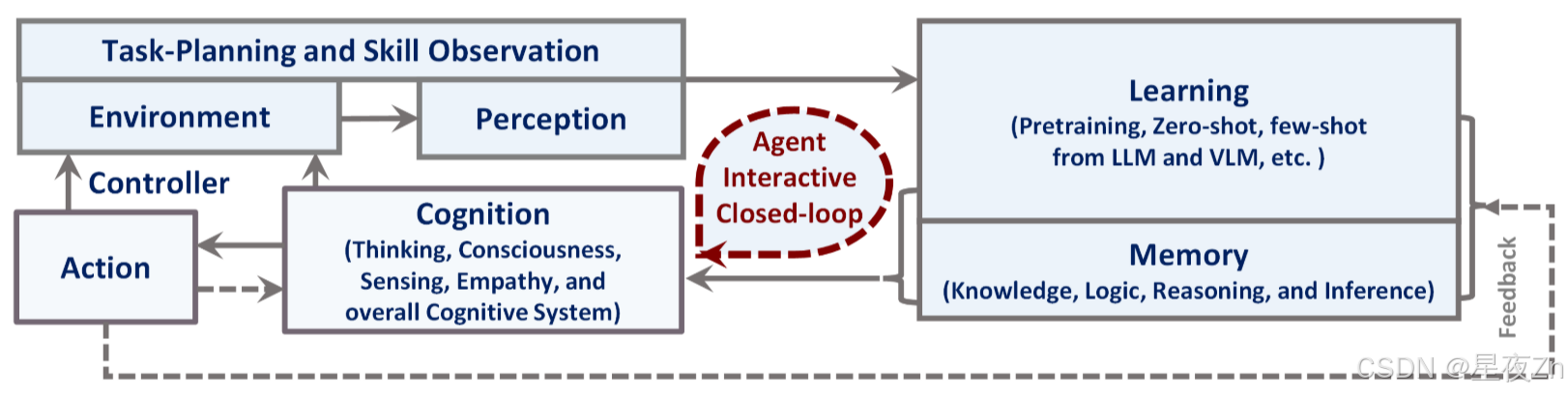
图5:我们提出的多模态通才代理的新代理范式。如图所示,有5个主要模块:1)环境和感知,包括任务规划和技能观察; 2)Agent学习; 3)记忆; 4)Agent行为; 5)认知。
3.1 LLMs and VLMs
我们可以使用LLM或VLM模型来引导Agent的组件,如图5所示。特别地,LLM已经显示出对于任务规划执行得很好(Gong等,2023a),包含了重要世界知识(Yu等人,2023b),并显示出令人印象深刻的逻辑推理能力(Creswell等人,2022年)的报告。另外,诸如CLIP的VLM(拉德福等人,2021)提供了一种语言对齐的通用视觉编码器,并提供了零触发视觉识别能力。例如,现有技术的开源多模态模型诸如LLaVA(Liu等人,2023c)和指令BLIP(Dai等人,2023)依赖于冻结的CLIP模型作为视觉编码器。
3.2 Agent Transformer Definition
代替将冻结的LLM和VLM用于AI代理,也可以使用单代理转换器模型,该模型将视觉标记和语言标记作为输入,类似于Gato(Reed等人,2022年)。除了视觉和语言之外,我们还添加了第三种一般类型的输入,我们将其表示为代理令牌。从概念上讲,智能体令牌用于为智能体行为预留模型输入输出空间的特定子空间。对于机器人或玩游戏,这可以表示为控制器的输入动作空间。在培训代理使用特定工具(如图像生成或图像编辑模型)或其他API调用时,也可以使用代理令牌。如图7所示,我们可以将代理令牌与视觉和语言令牌结合起来,生成一个统一的界面来训练多通道代理AI。与使用大型专有LLM作为代理相比,使用代理变压器有几个优势。首先,该模型可以很容易地定制为非常具体的代理任务,这些任务可能很难用自然语言表示(例如,控制器输入或其他特定动作)。因此,代理可以从环境交互和特定于领域的数据中学习以提高性能。其次,通过访问代理令牌的概率,可以更容易地理解模型执行或不执行特定操作的原因。第三,医疗保健和法律等某些领域对数据隐私有严格的要求。最后,相对较小的代理转换器可能比较大的专有语言模型要便宜得多。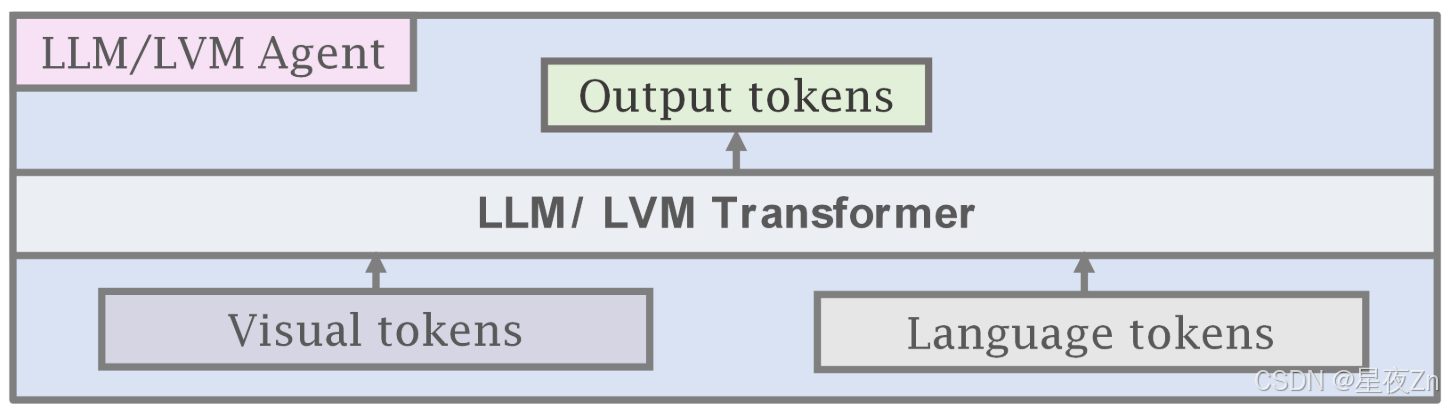
图六:我们展示了通过将大语言模型(LLM)与大视觉模型(LVM)相结合来创建多模态人工智能代理的当前范例。通常,这些模型接受视觉或语言输入,并使用预先训练和冻结的视觉和语言模型,学习连接和桥接模态的较小子网络。例子包括火烈鸟(Alayrac等人,2022)、BLIP-2(Li等人,2023 c),指令BLIP(Dai等人,2023)和LLaVA(Liu等人,第2023条c款)。
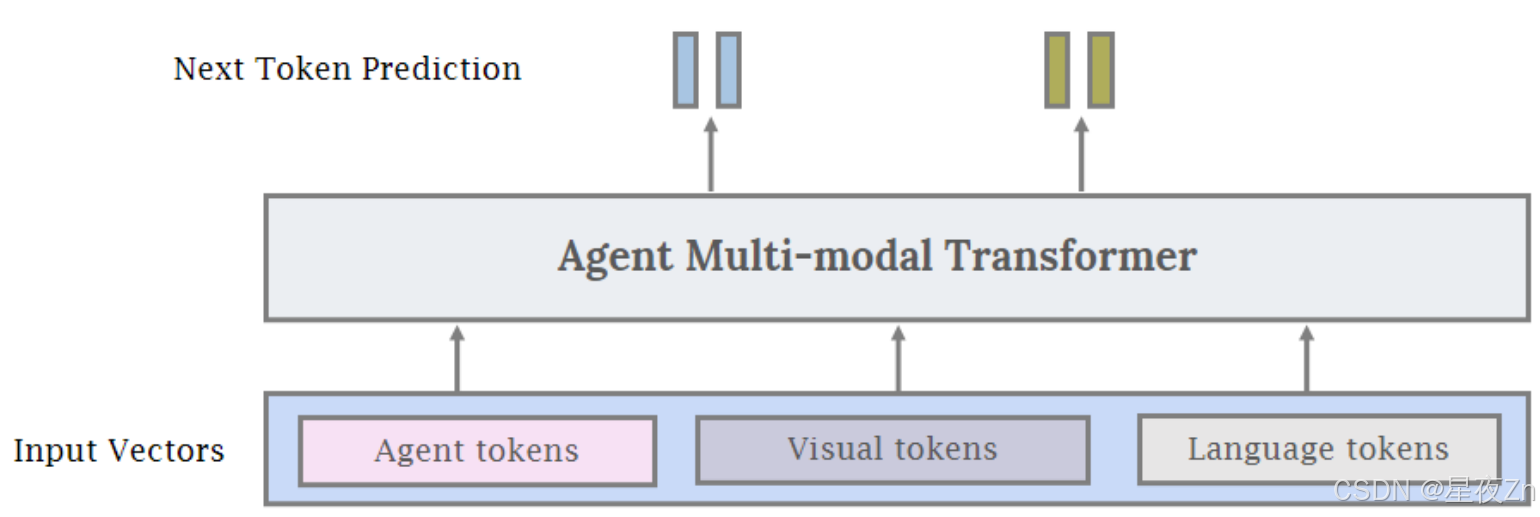
图7:统一代理多模态Transformer模型。本文提出了一种统一的、端到端的智能体系统训练范式,而不是将冻结的子模块连接起来,并使用现有的基础模型作为构建模块。我们仍然可以使用图6中的LLM和LVM初始化子模块,但也可以使用代理令牌,这些令牌用于训练模型在特定域中执行代理行为(例如,机器人学)。有关代理令牌的更多详细信息,请参见第3.2节
3.3 Agent Transformer Creation
如上图5所示,我们可以使用新的代理范例与LLM和VLM-bootstrapped代理,以及利用从大型基础模型生成的数据来训练代理Transformer模型,以学习执行特定目标。在这个过程中,代理模型被训练为专门的,并为特定的任务和领域量身定制。这种方法允许您利用预先存在的基础模型的学习特性和知识。我们通过以下两个步骤展示了该过程的简化概述:
定义域中的目标。为了训练代理Transformer,需要明确定义每个特定环境背景下代理的目标和动作空间。这包括确定代理需要执行哪些特定任务或操作,以及为每个任务或操作分配唯一的代理令牌。此外,可用于识别任务的成功完成的任何自动规则或过程可显著地改进可用于训练的数据量。否则,将需要基础模型生成的或人工注释的数据来训练模型。在收集数据并有可能评估代理的性能之后,持续改进的过程就可以开始了。
持续改进。持续监控模型的性能和收集反馈是该过程中的重要步骤。反馈应用于进一步的微调和更新。同样至关重要的是,要确保该模式不会使偏见或不道德的结果永久化。这就需要仔细检查训练数据,定期检查输出中的偏差,并在必要时训练模型以识别和避免偏差。一旦模型达到令人满意的性能,就可以为预期的应用程序部署它。持续监测对于确保模型按预期运行和促进必要的调整仍然至关重要。关于这一过程的更多细节、训练数据的来源以及围绕智能体AI的持续学习的细节可以在第8节中找到。
4 Agent AI Learning
4.1 Strategy and Mechanism
不同领域的交互式AI策略,扩展了使用经过训练的代理调用大型基础模型的范例,该代理积极寻求收集用户反馈,动作信息,有用的知识以进行生成和交互。有时,LLM/VLM模型不需要再次训练,我们通过在测试时为代理提供改进的上下文提示来提高它们的性能。另一方面,它总是涉及知识/推理/常识/推理交互式建模,通过三重系统的组合-一个从多模型查询执行知识检索,第二个从相关代理执行交互式生成,最后一个训练新的,信息丰富的自监督训练或预训练,采用强化学习或模仿学习改进的方式。
4.1.1 Reinforcement Learning (RL)
利用强化学习(RL)来训练具有智能行为的交互式智能体有着丰富的历史。RL是一种学习状态和行为之间的最佳关系的方法,该关系基于作为其行为的结果而接收到的奖励(或惩罚)。RL是一个高度可扩展的框架,已应用于包括机器人在内的众多应用,然而,它通常面临着几个领导者,LLM/VLM已经显示出缓解或克服其中一些困难的潜力:
- 奖励设计政策学习的效率在很大程度上取决于奖励函数的设计。设计奖励函数不仅需要RL算法的知识,还需要对任务性质的深入理解,因此通常需要基于专家经验来制作函数。几项研究探索了LLM/VLM在设计奖励函数中的应用(Yu等人,2023 a; Katara等人,2023年; Ma等人,2023年)的报告。
- 数据收集和效率鉴于其探索性质,基于RL的政策学习需要大量数据(Padalkar等人,2023年)的报告。当策略涉及管理长序列或集成复杂操作时,对大量数据的必要性变得尤为明显。这是因为这些情景需要更细致的决策,并从更广泛的情况中学习。在最近的研究中,努力的方向是加强数据生成,以支持政策学习(Kumar等人,2023; Du等人,2023年)的报告。此外,在一些研究中,这些模型已被整合到奖励函数中,以改善政策学习(Sontakke等人,2023年)的报告。与这些发展并行的是,另一个研究方向集中在使用VLM在学习过程中实现参数效率(Tang等人,2023年; Li等人,2023 d)和LLM(Shi等人,2023年)
- 关于数据效率的问题,随着动作序列长度的增加,RL变得更加具有挑战性。这是由于行动和回报之间的关系模糊,即所谓的学分分配问题,以及需要探索的状态数量的增加,需要大量的时间和数据。对于长时间且复杂的任务的一种典型方法是将它们分解成一系列子目标,并应用预先训练的策略来解决每个子目标(例如,(Takamatsu等人,2022年))。该思想福尔斯称为任务和运动规划(TAMP)的框架内(加勒特等人,2021年)的报告。TAMP由两个主要部分组成:任务规划,它需要识别高级动作的序列;运动规划,它涉及寻找物理上一致的、无冲突的轨迹以实现任务规划的目标。
LLM非常适合TAMP,并且最近的研究经常采用这样一种方法,其中LLM用于执行高级任务规划,而低级控制用基于RL的策略来解决(Xu等人,2023年; Sun等人,2023 a; Li等人,2023 b; Parakh等人,2023年)的报告。LLM的高级能力使它们能够有效地将甚至是抽象的指令分解成子目标(Wake等人,2023 c),有助于提高机器人系统中的语言理解能力。
4.1.2 Imitation Learning (IL)
RL的目标是训练基于探索性行为的策略,并通过与环境的交互来最大化回报,而模仿学习(IL)则寻求利用专家数据来模仿有经验的代理人或专家的行为。例如,在机器人技术中,基于IL的主要框架之一是行为克隆(BC)。BC是一种训练机器人通过直接模仿专家的动作来模仿他们的方法。在这种方法中,专家在执行特定任务时的动作被记录下来,机器人被训练成在类似的情况下重复这些动作。最新的基于业务连续性的方法通常采用LLM/VLM的技术,从而支持更高级的端到端模型。例如,Brohan等人提出了RT-1(Brohan等人,2022)和RT-2(Brohan等人,2023),基于变换器的模型,其输出基部和臂部的动作序列,将一系列图像和语言作为输入。这些模型在大量训练数据的基础上进行训练,结果显示出很高的泛化性能。
4.1.3 Traditional RGB
学习利用图像输入的智能代理行为多年来一直是人们感兴趣的(Mnih等人,2015年)的报告。使用RGB输入的固有挑战是维度的灾难。为了解决这个问题,研究人员要么使用更多的数据(Jang等人,2022年; Ha等人,2023)或在模型设计中引入感应偏置以提高样品效率。特别地,作者将3D结构结合到模型架构中以进行操作(Zeng等人,2021年; Shridhar等人,2023年; Goyal等人,2023年;詹姆斯和戴维森,2022年)。对于机器人导航,作者(Chaplot等人,2020 a,B)利用地图作为表示。可以从聚集所有先前RGB输入的神经网络或通过诸如神经辐射场的3D重建方法(Rosinol等人,2022年)的报告。
为了获得更多的数据,研究人员使用图形模拟器合成合成数据(Mu等人,2021年; Gong等人,2023 b),并试图缩小模拟与真实之间的差距(Tobin等人,2017; Sadeghi和Levine,2016; Peng等人,(2018年版)。最近,已经有一些集体努力来管理大规模数据集,其目的在于解决数据稀缺问题(Padalkar等人,2023年; Brohan等人,2023年)的报告。另一方面,为了提高样本的复杂性,也对数据扩增技术进行了广泛的研究(Zeng等人,2021; Rao等人,2020年; Haarnoja等人,2023年; Lifshitz等人,2023年)的报告。
4.1.4 In-context Learning
随着像GPT-3这样的大型语言模型的出现,语境中的学习被证明是解决NLP中的任务的有效方法(Brown等人,2020年; Min等人,2022年)的报告。通过在LLM提示的上下文中提供任务的示例,少击提示被视为将NLP中的各种任务的模型输出的上下文化的有效方式。诸如示例的多样性和为上下文内演示所示的示例的质量之类的因素可以提高模型输出的质量(An等人,2023年; Dong等人,2022年)的报告。在多模态基础模型的背景下,诸如Flamingo和BLIP-2的模型(Alayrac等人,2022年; Li等人,2023 c)在仅给出少量示例时在多种视觉理解任务中是有效的。通过在采取某些动作时结合环境特定的反馈,可以进一步改进环境中的代理的上下文学习(Gong等人,第2023条a款)。
4.1.5 Optimization in the Agent System
智能体系统的优化可以分为空间和时间两个方面。空间优化考虑代理如何在物理空间内操作以执行任务。这包括机器人之间的协调、资源分配和保持有组织的空间。
为了有效地优化代理人工智能系统,特别是大量代理并行操作的系统,以前的工作主要集中在使用大批量强化学习(Shacklett等人,2023)。由于特定任务的多代理交互数据集很少,因此自我发挥强化学习使一组代理能够随着时间的推移而改进。然而,这也可能导致非常脆弱的代理,只能在自我游戏下工作,而不能与人类或其他独立代理一起工作,因为它们过于适应自我游戏训练范式。为了解决这个问题,我们可以发现一套不同的惯例(Cui等人,2023;Sarkar等人,2023),并培训一名了解广泛惯例的代理人。基础模型可以进一步帮助与人类或其他独立代理建立约定,从而实现与新代理的顺利协调。
另一方面,时间优化关注的是代理如何随着时间的推移执行任务。这包括任务调度、排序和时间线效率。例如,优化机器人手臂的轨迹是有效地优化连续任务之间的运动的一个例子(周等人,2023c)。在任务调度层面,已经提出了LLM-DP(Dagan等人,2023)和Reaction(姚等人,2023a)等方法,通过交互地纳入环境因素来解决有效的任务规划。
4.2 Agent Systems (zero-shot and few-shot level)
4.2.1 Agent Modules
我们对Agent范式的探索涉及到使用LLM或VLM为交互式多模态Agent开发Agent AI“模块”。我们的初始代理模块有助于培训或情境学习,并采用了最低限度的设计,以展示代理的能力,以安排和协调有效。我们还探索了最初的基于提示的记忆技术,这些技术有助于更好地规划和告知领域内未来的行动方法。为了说明,我们的“MindAgent”基础结构包括5个主要模块:1)环境感知和任务规划,2)Agent学习,3)记忆,4)一般Agent行为预测和5)认知,如图5所示。
4.2.2 Agent Infrastructure
基于Agent的人工智能是一个大型的、快速发展的社区,在娱乐、研究和工业领域都有广泛的应用。大型基础模型的发展显著提高了智能体人工智能系统的性能。然而,以这种方式创建代理受到创建高质量数据集所需的不断增加的工作量和总成本的限制。在Microsoft,构建高质量的代理基础架构通过使用先进的硬件、多样化的数据源和功能强大的软件库,对多模式代理副本产生了重大影响。随着微软不断推进代理技术的边界,AI代理平台在未来几年仍将是多模式智能世界的主导力量。尽管如此,智能体AI交互目前仍然是一个复杂的过程,需要多种技能的组合。大型生成式人工智能模型领域的最新进展有可能大幅降低大型工作室当前交互式内容所需的高成本和时间,并使规模较小的独立内容创作者能够设计出超出其当前能力的高质量体验。目前多模态智能体内部的人机交互系统主要是基于规则的。它们确实具有响应人类/用户动作的智能行为,并在一定程度上拥有网络知识。然而,这些交互通常受到软件开发成本的限制,以实现系统中的特定行为。此外,当前的模型并不是设计成在用户不能实现特定任务的情况下帮助人类实现目标。因此,需要一个代理人工智能系统基础设施来分析用户行为、并在需要时提供适当的支持。
4.3 Agentic Foundation Models (pretraining and finetune level)
使用预先训练的基础模型在其跨不同用例的广泛适用性方面提供了显著的优势。这些模型的集成使得能够为各种应用开发定制的解决方案,从而避免了为每个特定任务需要大量的标记数据集。
在导航领域中的一个显著的例子是LM-Nav系统(Shah等人,2023 a),其在一种新的方法中掺入了GPT-3和CLIP。它有效地使用语言模型生成的文本地标,将它们锚定在机器人获取的图像中进行导航。该方法展示了文本和视觉数据的无缝融合,显著增强了机器人导航的能力,同时保持了广泛的适用性。
在机器人操纵中,一些研究已经提出使用现成的LLM(例如,ChatGPT),同时使用开放词汇对象检测器。LLM和高级物体探测器(例如,Detic(Zhou等人,2022))促进了对人类指令的理解同时将文本信息建立在风景信息的基础上(Parakh等人,2023年)的报告。此外,最新的进展展示了将即时工程与诸如GPT-4V(ision)的高级多模态模型(Wake等人,第2023段b)。该技术为多模态任务规划开辟了道路,强调了预训练模型在各种上下文中的通用性和适应性。
5 Agent AI Categorization
5.1 Generalist Agent Areas
基于计算机的行动和通才代理(GAs)对许多任务都很有用。大型基础模型和交互式人工智能领域的最新进展为遗传算法带来了新的功能。然而,要使GA对用户真正有价值,它必须能够自然地与广泛的上下文和模态进行交互,并将其推广到广泛的上下文和模态。我们高质量地扩展了第6节中关于智能体基础AI的主要章节,特别是与这些主题的一般主题相关的领域:
Multimodal Agent AI(MMA)是一个即将到来的论坛,供我们的研究和行业社区相互交流,并与Agent AI中更广泛的研究和技术社区进行交流。大型基础模型和交互式AI领域的最新进展为通用代理(GA)提供了新的功能,例如预测用户操作和约束设置中的任务规划(例如,MindAgent(Gong等人,2023 a)、细粒度多模态视频理解(Luo等人,2022)、机器人技术(Ahn等人,2022 b; Brohan等人,2023)),或者为用户提供结合了知识反馈的聊天伙伴(例如,用于医疗保健系统的网站客户支持(Peng等人,2023年))。更多代表作及近期代表作详情如下。我们希望讨论我们对MAA未来的愿景,并激励未来的研究人员在这一领域工作。这篇文章和我们的论坛涵盖了以下主要主题,但不仅限于这些:
- 主要主题:多模式代理AI,通用代理AI
- 二级主题主题:智能代理,动作代理,基于智能的代理,视觉和语言代理,知识和推理代理,游戏代理,机器人,医疗保健等
- 扩展主题:视觉导航,仿真环境,重排,机器人基础模型,VR/AR/MR,智能视觉和语言。
接下来,我们将介绍以下代表性代理类别的具体列表:
5.2 Embodied Agents
我们的生物思想生活在身体中,我们的身体在不断变化的世界中移动。具体化人工智能的目标是创建代理,如机器人,学习创造性地解决需要与环境交互的挑战性任务。虽然这是一个重大挑战,但深度学习的重要进展以及ImageNet等大型数据集的可用性不断提高,使人们能够在以前认为棘手的各种人工智能任务上实现超人的性能。计算机视觉、语音识别和自然语言处理在语言翻译和图像分类等被动输入输出任务中经历了变革性的革命,强化学习在游戏等交互式任务中也取得了世界级的性能。这些进步为嵌入式人工智能提供了动力,使越来越多的用户能够在智能代理与机器交互方面取得快速进展。
5.2.1 Action Agents
动作智能体是指需要在模拟的物理环境或真实的世界中执行物理动作的智能体。特别是,它们需要积极参与与环境有关的活动。根据应用领域的不同,我们将动作代理大致分为两类:游戏AI和机器人。
在游戏AI中,代理将与游戏环境和其他独立实体进行交互。在这些环境中,自然语言可以实现代理和人类之间的顺畅通信。根据游戏的不同,可能会有一个特定的任务要完成,提供一个真正的奖励信号。例如,在竞争性的外交游戏中,使用人类对话数据沿着RL的动作策略来训练语言模型使得能够进行人类级别的游戏(Meta Fundamental AI Research(FAIR)Diplomacy Team等人,2022年)的报告。
也存在我们代理人充当城镇中的普通居民的设置(Park等人,2023a),而不试图优化特定的目标。基础模型在这些设置中非常有用,因为它们可以通过模拟人类行为来模拟看起来更自然的交互。当外部记忆被增强时,他们会产生令人信服的代理人,这些代理人可以进行对话、安排日程、建立关系,并拥有虚拟生活。
5.2.2 Interactive Agents
交互式代理简单地指可以与世界交互的代理,这是一个比行动代理更广泛的代理类别。它们的交互形式不一定需要物理动作,但可能涉及向用户传达信息或修改环境。例如,具体化的交互式代理可以通过对话回答用户关于主题的问题,或者类似于聊天机器人帮助用户解析现有信息。通过扩展代理的能力以包括信息共享,代理AI的核心设计和算法可以有效地适用于一系列的应用,例如诊断(Lee等人,2023)和知识检索(Peng等人,2023年)代理商。
5.3 Simulation and Environments Agents
人工智能主体学习如何在环境中行动的一种有效方法是通过与环境的交互经历试错经验。一种代表性的方法是RL,其需要大量的失败经验来训练代理。尽管存在使用物理试剂的方法(Kalashnikov等人,2018年),使用物理代理耗时且成本高昂。此外,当在实际环境中的失败可能是危险的(例如,自动驾驶、水下航行器)。因此,使用模拟器来学习策略是一种常见的方法。
已经提出了许多仿真平台用于研究嵌入式AI,范围从导航(Tsoi等人,2022年; Deitke等人,2020年; Kolve等人,2017)到对象操作(Wang等人,2023年d; Mees等人,2022年; Yang等人,2023 a; Ehsani等人,2021年)的报告。一个例子是Habitat(Savva等人,2019年; Szot等人,2021),其提供了3D室内环境,其中人类和机器人代理可以执行诸如导航、指令跟随和问题回答之类的各种任务。另一个代表性的仿真平台是VirtualHome(Puig等人,2018年),支持在3D室内环境中操纵物体的人类化身。在游戏领域,卡罗尔等人已经引入了“Overcooked-AI”,这是一种设计用于研究人类和AI之间的合作任务的基准环境(卡罗尔等人,(2019年版)。沿着类似的路线,一些工作的目的是将真实的的人的干预纳入到主体和环境之间的相互作用的焦点之外(Puig等人,2023年; Li等人,2021年a; Srivastava等人,2022年)的报告。这些模拟器有助于在涉及代理和机器人交互的实际环境中学习策略,以及利用人类示范动作进行基于IL的策略学习。
在某些情况下,学习策略的过程可能需要在模拟器中集成专门的功能。例如,在学习基于图像的策略的情况下,经常需要逼真的渲染来促进对真实的环境的适应性(Mittal等人,2023年; Zhong等人,2023年)的报告。利用逼真渲染引擎对于生成反映诸如照明环境的各种条件的图像是有效的。此外,需要使用物理引擎的模拟器来模拟与对象的物理交互(Liu和Negrut,2021)。模拟中物理引擎的集成已经被证明有助于获得可应用于真实世界场景的技能(Saito等人,2023年)的报告。
5.4 Generative Agents
大型生成式人工智能模型领域的最新进展有可能大大降低大型游戏工作室当前交互式内容所需的高成本和时间,并使小型独立工作室能够创建超出其目前能力的高质量体验。此外,在沙盒环境中嵌入大型人工智能模型,将允许用户创作自己的体验,并以目前遥不可及的方式表达他们的创造力。这个代理的目标不仅仅是简单地将交互式3D内容添加到场景中,还包括:
- 为对象添加任意行为和交互规则,允许用户在最小提示的情况下创建自己的VR规则。
- 通过使用多模态GPT 4-v模型以及涉及视觉AI模型的其他模型链,从一张纸上的草图生成整个层次的几何体。
- 使用扩散模型对场景中的内容进行重纹理化·从简单的用户提示创建自定义着色器和视觉特效。
短期内的一个潜在应用是VR创建故事板/原型工具,允许单个用户创建体验/游戏的粗略(但功能)草图,速度比目前可行的快一个数量级。这样一个原型然后可以扩大,并使更抛光使用这些工具以及。
5.4.1 AR/VR/mixed-reality Agents
AR/VR/混合现实(统称为XR)设置当前需要熟练的艺术家和动画师来创建角色、环境和对象,以用于对虚拟世界中的交互进行建模。这是一个成本高昂的过程,涉及概念艺术、3D建模、纹理、装配和动画。XR代理可以通过促进创建者和构建工具之间的交互来帮助构建最终的虚拟环境,从而在此过程中提供帮助。
我们的早期实验已经证明GPT模型可以在Unity引擎内部的少量拍摄区域中使用(无需任何额外的微调),以调用引擎特定的方法,使用API调用从互联网下载3d模型并将其放置到场景中,并为它们分配行为和动画的状态树(Huang等人,第2023条a款)。出现这种行为可能是因为在使用Unity的开源游戏存储库中存在类似的代码。因此,GPT模型能够通过从简单的用户提示将许多对象加载到场景中来构建丰富的视觉场景。
这类代理的目标是构建一个平台和一组工具,在大型AI模型(包括GPT系列模型和扩散图像模型)和渲染引擎之间提供有效的接口。我们在此探讨两个主要途径:
- 将大型模型集成到代理基础设施中的各种编辑器工具中,从而大大加快了开发速度。
- 通过生成遵循用户指令的代码,然后在运行时对其进行编译,从用户体验中控制渲染引擎,从而允许用户以任意方式编辑他们正在交互的VR/模拟,甚至通过引入新的代理机制。
引入一个专注于XR设置的AI副驾驶对XR创作者来说会很有用,他们可以使用副驾驶来完成繁琐的任务,比如提供简单的资产或编写代码样板,让创作者专注于他们的创意愿景,并快速迭代想法。
此外,代理还可以通过添加新资产、更改环境动态或构建新设置,帮助用户交互式地修改环境。这种在运行时动态生成的形式也可以由创建者指定,从而使用户的体验能够感到新鲜并随着时间的推移而继续发展。
5.5 Knowledge and Logical Inference Agents
推理和应用知识的能力是人类认知的一个定义性特征,在逻辑推理和理解心理理论等复杂任务中尤为明显。对知识进行推断可以确保人工智能的反应和行动与已知事实和逻辑原则一致。这种一致性是维持人工智能系统信任和可靠性的关键机制,特别是在医疗诊断或法律的分析等关键应用中。在这里,我们介绍的代理,将知识和推理,解决特定方面的智能和推理之间的相互作用。
5.5.1 Knowledge Agent
知识代理从两个方向对获取的知识系统进行推理:隐式推理和显式推理。隐含知识通常是诸如GPT系列的大规模语言模型(Brown等人,2020; OpenAI,2023)在对大量文本数据进行训练后进行封装。这些模型可以产生给人理解的印象的反应,因为它们利用了在培训期间隐性学习的模式和信息。相反,显性知识是结构化的,可以直接查询,比如在知识库或数据库中找到的信息,传统上是通过引用可验证的外部资源来增强AI推理能力。
尽管语言模型取得了进步,但它们的隐含知识是静态的,并且随着世界的演变而变得过时(刘易斯等人,2020年; Peng等人,2023年)的报告。这一限制需要整合不断更新的显性知识源,以确保人工智能系统能够提供准确和最新的响应。隐性和显性知识的融合使AI代理具备了更细致入微的理解和在上下文中应用知识的能力,类似于人类智能(Gao等人,2022年)的报告。这种整合对于打造以知识为中心的人工智能代理至关重要,这些代理不仅拥有信息,而且能够理解、解释和使用信息,从而缩小广泛学习和渊博知识之间的鸿沟(Marcus和Davis,2019; Gao等人,2020年)的报告。这些智能体被设计为利用关于世界的灵活性和动态信息进行推理,从而增强了它们的鲁棒性和适应性(Marcus,2020)。
5.5.2 Logic Agents
通常,逻辑代理是被设计为应用逻辑推理来处理数据或解决特定于逻辑推理或逻辑推理的任务的系统的组件。在大型基础模型(如GPT-4)的上下文中,逻辑代理是指专门用于处理逻辑推理任务的组件或子模块。这些任务通常涉及理解和处理抽象概念、从给定前提推导出结论,或者解决需要结构化、逻辑化方法的问题。从广义上讲,像GPT-4这样的基础模型是在大量文本数据的基础上训练的,并学习执行各种任务,包括那些需要某种形式的逻辑推理的任务。因此,它们的逻辑推理能力被集成到整个体系结构中,并且它们通常不具有独特的、孤立的“逻辑代理”。虽然GPT-4和类似模型可以执行涉及逻辑的任务,但它们的方法与人类或传统的基于逻辑的系统的操作方式有根本不同。它们不遵循形式逻辑规则,也不对逻辑有明确的理解;相反,它们基于从训练数据中学习到的模式生成响应。因此,它们在逻辑任务中的性能可能令人印象深刻,但也可能不一致或受到训练数据的性质和模型设计的固有限制的限制。将单独的逻辑子模块嵌入到体系结构中的一个示例是(Wang等人,2023 e),其通过将文本解析成逻辑段并显式地对令牌嵌入中的逻辑层次结构进行建模来修改在预训练期间由LLM使用的令牌嵌入过程。
5.5.3 Agents for Emotional Reasoning
在许多人机交互中,情感理解和移情是Agent的重要技能。为了说明,创建参与对话代理的一个重要目标是使代理以增加的情感和同理心行动,同时最小化社交不适当或攻击性输出。为了向对话主体的这一目标前进,我们发布了具有移情的神经图像评论(NICE)数据集(Chen等人,2021年),由近两百万张图片和相应的人工生成的评论以及一组人类情感注释组成。我们还提供了一种新颖的预训练模型–对图像评论的影响生成建模(MAGIC)(Chen等人,2021),其目的是为图像生成评论,以捕捉风格和影响的语言表示为条件,并帮助生成更具同情心、情感化、吸引人和社交适当的评论。实验结果表明,该方法能够有效地训练出更人性化、更吸引人的图像评论Agent。发展移情感知Agent是交互式Agent的一个很有前途的方向,特别是考虑到当前许多语言模型在其情感理解和移情推理能力上表现出偏差,因此创建具有跨广泛群体和人群的情感理解能力的Agent是很重要的(Mao et al.,2022年; Wake等人,(第2023段d)。
5.5.4 Neuro-Symbolic Agents
神经符号代理在神经元和符号的混合系统上运行(d 'Avila Garcez和Lamb,2020)。解决自然语言中的问题是一项具有挑战性的任务,因为它需要显式地捕获隐含在输入中的离散符号结构信息。然而,大多数一般的神经序列模型并没有明确地捕获这样的结构信息,限制了它们在这些任务上的性能。这项工作(Chen等人,2020)提出了一种基于结构化神经表示Agent的编码-解码模型,TP-N2 F的编码器采用TPR“绑定”对向量空间中的自然语言符号结构进行编码,解码器采用TPR“解绑定”在符号空间中生成由关系元组表示的序列程序,每个关系元组由一个关系(或操作)和若干个自变量组成。
GPT-4等指令跟随视觉语言(VL)模型提供了灵活的界面,以零触发的方式支持广泛的多模态任务。然而,在完整图像上操作的界面不能直接使用户“指向”和访问图像内的特定区域。这种能力不仅对于支持参考接地VL基准测试非常重要,而且对于需要精确图像内推理的实际应用也非常重要。在(Park等人,2023 b)中,我们建立了允许用户指定(多个)区域作为输入的本地化Visual Commonsense模型。我们通过从大型语言模型(LLM)中采样本地化常识知识来训练我们的模型:具体地说,我们提示LLM收集常识知识,给定由一组VL模型自动生成的全局文字图像描述和局部文字区域描述。此管道是可伸缩的,并且是全自动的,因为不需要对齐或人工创作的图像和文本对。通过一个单独训练的、选择高质量示例的评论模型,我们发现,在仅从图像扩展的本地化常识语料库上的训练可以成功地提取现有的VL模型,以支持作为输入的参考接口。实验结果和在零触发设置下的人类评估表明,与传递所生成的指称表达式的基线相比,我们的提取方法产生了更精确的推理VL模型。
5.6 LLMs and VLMs Agent
许多工作利用LLM作为代理来执行任务规划(Huang等人,2022 a; Wang等人,2023 b; Yao等人,2023 a; Li等人,2023 a),并利用LLM的大规模互联网领域知识和零机会规划能力来执行代理任务,如规划和推理。最近的机器人研究还利用LLM来执行任务规划(Ahn等人,2022 a; Huang等人,2022 b; Liang等人,2022),通过将自然语言指令分解成自然语言形式或Python代码的子任务序列,然后使用低级控制器来执行这些子任务。另外,(Huang等人,2022 b),(Liang等人,2022年),以及(Wang等人,2023 a)还结合了环境反馈以改进任务性能。也有许多工作证明了在大规模文本、图像和视频数据上训练的通用视觉对齐的大语言模型的能力,以用作创建多模态代理的基础,所述多模态代理被具体化并且可以在各种环境中起作用(Baker等人,2022年; Driess等人,2023年; Brohan等人,2023年)的报告。
6 Agent AI Application Tasks
6.1 Agents for Gaming
游戏提供了一个独特的沙箱来测试LLM和VLM的代理行为,推动他们的协作和决策能力的界限。我们描述了三个领域,特别是突出代理的能力,与人类球员和其他代理,以及他们的能力,在一个环境中采取有意义的行动。
6.1.1 NPC Behavior
在现代游戏系统中,非玩家角色(NPC)的行为主要由开发人员精心制作的预定义脚本决定。这些脚本包含基于游戏环境中各种触发器或玩家动作的一系列反应和交互。然而,这种脚本化的性质通常会导致可预测或重复的NPC行为,这些行为无法响应玩家的动作或游戏的动态环境。这种刚性阻碍了动态游戏环境中的沉浸式体验。因此,人们越来越有兴趣利用LLM来诱导NPC行为的自主性和适应性,使互动更加细致入微和引人入胜。AI驱动的NPC可以从玩家行为中学习,适应不同的策略,并提供更具挑战性和更少可预测性的游戏体验。大型语言模型(LLM)可以显著促进游戏中NPC行为的发展。通过处理大量的文本,LLM可以学习模式并生成更多样化和更人性化的响应。它们可以用来创建动态对话系统,使与NPC的互动更具吸引力,更不可预测。此外,LLM可以根据玩家反馈和游戏中的数据进行训练,以不断改进NPC的行为,使其更加适应玩家的期望和游戏动态。
6.1.2 Human-NPC Interaction
人类玩家和NPC之间的互动是游戏体验的一个重要方面。传统的互动模式主要是一维的,NPC以预设的方式对玩家的输入做出反应。这种限制扼杀了更有机和丰富的互动的潜力,类似于虚拟领域中的人与人的互动。LLM和VLM技术的出现有望改变这种模式。通过采用这些技术,游戏系统可以分析和学习人类行为,以提供更人性化的交互。这不仅增强了游戏的真实感和参与度,还为在受控但复杂的环境中探索和理解人机交互提供了平台。
6.1.3 Agent-based Analysis of Gaming
游戏是日常生活中不可或缺的一部分,估计吸引了世界一半的人口。此外,它对心理健康也有积极的影响。然而,当代游戏系统在与人类玩家的交互方面表现出不足,因为他们的行为主要是由游戏开发者手工制作的。这些预先设定好的行为经常不能适应玩家的需要。因此,游戏中需要新的AI系统,可以分析玩家行为并在必要时提供适当的支持。智能交互系统有可能彻底改变玩家与游戏系统的交互方式。NPC与玩家的互动不再受游戏开发者设计的限制规则的限制。它们有潜力无缝适应玩家的体验,提供及时的反馈,以丰富游戏体验并提升人机交互的协同作用。
LLM可以作为分析游戏中文本数据的强大工具,包括聊天记录,玩家反馈和叙事内容。它们可以帮助识别玩家行为、偏好和交互的模式,这对游戏开发人员改善游戏机制和叙事是非常宝贵的。此外,VLM可以解析来自游戏会话的大量图像和视频数据,以帮助分析游戏世界中的用户意图和动作。此外,LLM和VLM可以促进游戏中智能代理的开发,这些智能代理可以以复杂和人性化的方式与玩家和其他代理进行通信,从而增强整体游戏体验。除了LLM和VLM之外,用户输入数据为创建游戏代理提供了一个有前途的途径,这些代理通过模仿人类玩家来模拟感知,游戏和游戏理解。通过整合玩家交互和反馈、像素输入以及自然语言规划和理解的组合,智能体模型可以帮助持续改进游戏动态,推动游戏环境以玩家为中心的演变。
6.1.4 Scene Synthesis for Gaming
场景合成是创建和增强沉浸式游戏环境的重要组成部分。它需要在游戏中自动或半自动地生成三维(3D)场景和环境。此过程包括地形的生成、对象的放置、真实照明的创建,有时甚至包括动态天气系统。
现代游戏通常以广阔、开放的世界环境为特色。手动设计这些环境可能非常耗时且资源密集。自动地形生成通常利用程序或人工智能驱动的技术,可以生成复杂、逼真的地形,而人工工作量更少。LLM和VLM可以利用互联网尺度知识制定规则来设计视觉上令人印象深刻且独特的非重复景观。此外,可以使用LLM和VLM来确保所生成的资产的语义一致性和可变性.以逼真且美观的方式在场景中放置对象(如建筑物、植被和其他元素)对于沉浸效果至关重要。
VLM和LLM可以通过遵守预定义或学习的规则和美学来帮助对象放置,从而加快关卡设计过程。VLM和LLM可以进一步接受培训,以了解设计和美学原则,帮助内容的程序生成。它们可以帮助制定规则或指导方针,程序算法可以遵循这些规则或指导方针来生成既具有视觉吸引力又适合上下文的对象和场景。
逼真的灯光和大气效果是创建可信且引人入胜的游戏环境的基础。高级算法可以模拟自然光照条件和动态天气效果,增强场景的真实感和氛围。LLM可以帮助开发系统,以几种创新的方式获得更逼真的照明和大气效果。VLM可以分析来自真实世界照明和大气条件的大量数据集,以帮助开发更逼真的算法,在游戏中模拟这些效果。通过了解自然光照和天气的模式和复杂性,这些模型可以为开发密切模拟现实的算法做出贡献。LLM和VLM还可用于开发基于玩家动作、游戏状态或外部输入实时调整照明和气氛效果的系统。它们可以处理来自玩家的自然语言命令,以修改游戏环境,提供更具交互性和身临其境的体验。
6.1.5 Experiments and Results
使用LLM或LVM进行零次/少次学习。如图8和图9所示,我们使用GPT-4V进行高级描述和动作预测。图8显示了使用GPT-4V生成和编辑动作描述的一些定性示例。代理增强文本开辟了一种新的方法,用游戏动作先验生成3D场景,以帮助提高场景的自然度。因此,GPT-4V生成适合游戏视频的相关高级描述。

图8:通过GPT-4V进行Minecraft Dungeons游戏感觉模拟和生成的用户交互式游戏动作预测和交互式编辑的具体代理。

图9:GPT-4V可以有效地预测高层次的下一个动作时,给定的“行动历史”和“游戏目标”的提示。此外,GPT-4V准确地识别出玩家手中拿着的是木头,并可以将这些感知到的信息纳入其未来行动的计划中。虽然GPT-4V似乎能够预测一些低级动作(例如按下“E”打开库存),但模型的输出本身并不适合原始低级动作预测(包括鼠标移动),并且可能需要补充模块进行低级动作控制。
小代理预训练模型。为了展示我们的代理视觉语言架构,我们首先通过对Minecraft数据进行预训练来研究其在游戏代理广泛使用的领域中的应用。如图7所示,给定输入的动作主体、视频的关键帧和相应的文本,可以采用标准的编码器-解码器将主体动作和图像转换为动作文本令牌和图像补丁令牌,然后使用主体-视觉-语言解码器将其转换为动作预测语句。图7中描绘了总体架构。我们通过几个Minecraft演示来评估我们的方法。Minecraft视频数据由5分钟的剪辑组成,我们用于预训练的视频包含78 K视频,我们使用5 K视频(预训练数据的6%)进行第一轮预训练。我们在16个NVIDIA v100 GPU上训练了一天的250 M参数模型,并在图10和图11中可视化了我们的模型输出。图10显示了我们相对较小的代理架构可以为训练期间看不到的Minecraft场景产生合理的输出。图11显示了与地面真实人类玩家动作相比的模型预测,表明对我们的小型代理模型的潜在低水平理解。

图10:未看过的《我的世界》视频的屏蔽视频预测。从左到右:原始帧、遮罩帧、重建帧和带面片的重建帧。
图11:在游戏Minecraft场景中使用小型智能体预训练模型的低级下一步动作预测。

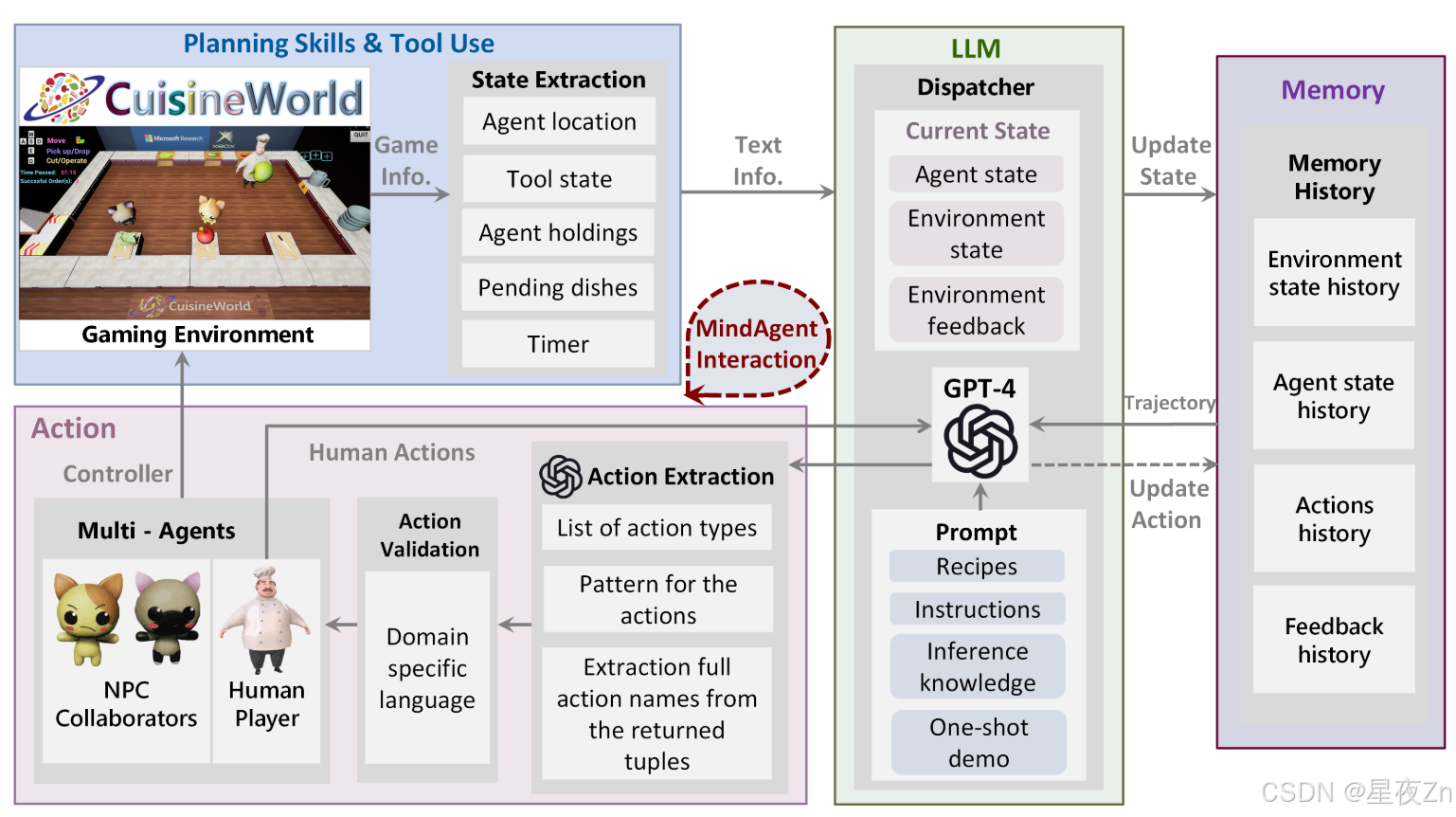
图12:情境学习游戏基础设施的MindAgent。规划技能和工具用途:游戏环境需要不同的规划技能和工具使用来完成任务。它生成相关的游戏信息,并将游戏数据转换为LLM可以处理的结构化文本格式。LLM:我们的基础设施的主要主力做出决策,因此作为多代理系统的调度器。Memory History:相关信息的存储工具。行动模块:从文本输入中提取操作,并将其转换为特定于域的语言,并验证DSL,以便它们在执行期间不会导致错误。
多代理基础架构。如图5中的代理范例所示,我们为称为“CuisineWorld”的新游戏场景设计了新颖的基础结构(Gong等人,第2023条a款)。我们在图12中详细描述了我们的方法。我们的基础设施允许多代理协作,利用GPT-4作为一个中央规划器,并跨多个游戏域工作。我们研究了我们的系统的多智能体规划能力,并将该基础设施部署到现实世界的视频游戏中,以证明其多智能体和人-AI协作的有效性。此外,我们还介绍了“Cuisineworld”,一个基于文本的多Agent协作基准测试,它提供了一个新的自动度量协作评分(CoS)来量化协作效率。
请参阅附录,了解更多游戏描述、高级动作预测和GPT-4V提示的示例和详细信息。我们在图32和附录B中给出了“出血边缘”的例子,在图33和附录C中给出了微软的飞行模拟器的例子,在图34和附录D中给出了ASSASSIN的CREED ODYSSEY的例子,在图35和附录E中给出了“战争的齿轮4”的例子,在图36和附录F中给出了“星域”的例子。我们还提供了一个详细的屏幕截图的提示过程,为GPT 4V用于生成Minecraft的例子与图31在附录A中。
6.2 Robotics
机器人是需要与环境进行有效交互的代表性代理。在本节中,我们将介绍高效机器人操作的关键要素,回顾应用最新LLM/VLM技术的研究主题,并分享我们最新研究的发现。
视觉运动控制。视觉运动控制是指在机器人系统中将视觉感知和运动动作相结合以有效地执行任务。这种集成是至关重要的,因为它使机器人能够解释来自其环境的视觉数据,并相应地调整其运动动作,以与环境准确地互动。例如,在装配线上,配备了视觉电机控制的机器人可以感知物体的位置和方向,并精确地对准其机械手以与这些物体进行交互。这一能力对于确保机器人在各种应用中的精确性和有效性至关重要,从工业自动化到帮助老年人完成日常家务。此外,视觉运动控制有助于机器人适应动态环境,其中环境的状态可能会迅速变化,需要基于视觉反馈对运动动作进行实时调整。
此外,在安全操作的背景下,视觉信息对于检测执行错误和确认每个机器人动作的前置和后置条件至关重要。在不受控制的环境中,例如未知的家庭环境,由于不可预测的因素,如改变家具形状,变化的照明和滑动,机器人更有可能面临意想不到的结果。仅以前馈方式执行预先计划的行动计划可能会在这些环境中造成重大风险。因此,利用视觉反馈不断验证每一步的结果是确保机器人系统稳健可靠运行的关键。
语言条件操纵。语言条件操作需要机器人系统基于语言指令解释和执行任务的能力。这一点对于为人机交互创建直观和用户友好的界面尤为重要。通过自然语言命令,用户可以以类似于人与人通信的方式向机器人指定目标和任务,从而降低了操作机器人系统的障碍。例如,在实际情况中,用户可以指示服务机器人“从桌子上拿起红苹果,”并且机器人将解析该指令,识别所涉及的对象并执行将其拿起的任务(Wake等人,第2023条c款)。核心挑战在于开发强大的自然语言处理和理解算法,这些算法可以准确地解释从直接命令到更抽象的指令等各种指令,并使机器人能够将这些指令转换为可操作的任务。此外,确保机器人能够在不同的任务和环境中推广这些指令,对于增强其在现实世界应用中的多功能性和实用性至关重要。使用语言输入来指导机器人的任务规划在被称为任务和运动规划的机器人框架的上下文中已经引起了注意(加勒特等人,2021年)的报告。
技能优化。最近的研究强调了LLM在机器人任务规划中的有效性。然而,任务的最佳执行,特别是那些涉及物理交互(如抓取)的任务,需要对环境有更深的理解,而不仅仅是解释人类指令。例如,机器人抓取需要精确的接触点(Wake等人,2023e)和手臂姿势(Sasabuchi等人,2021)以有效地执行后续动作。虽然这些元素–精确的接触点和手臂姿势–对人类来说是直观的,但通过语言表达它们是具有挑战性的。尽管互联网规模的VLM取得了进步,但从场景中捕捉这些细微的间接线索并将其有效地转化为机器人技能仍然是一个重大挑战。作为响应,机器人社区越来越关注收集增强的数据集(例如,(Wang等,2023 d; Padalkar等人,2023))或开发用于从人类示范直接获得技能的方法(Wake等人,2021年a)。示范学习和模仿学习等教学模式引领着体育教学的发展,在体育技能优化中发挥着重要作用。
6.2.1 LLM/VLM Agent for Robotics.
最近的研究已经证明了LLM/VLM在机器人代理中的潜力,涉及在环境中与人类的交互。旨在利用最新LLM/VLM技术的研究主题包括:
多模态系统:最近的研究一直在积极地关注开发端到端系统,这些系统将最新的LLM和VLM技术作为输入信息的编码器。特别地,存在修改这些基础模型以处理多模态信息的显著趋势。(Jiang等人,2022年; Brohan等人,2023年、2022年; Li等人,2023 d; Ahn等人,2022 b; Shah等人,2023 b; Li等人,2023年e月)。该适应性修改旨在基于语言指令和视觉线索两者来引导机器人动作,从而实现有效的实施例。
任务规划和技能培训:与端到端系统相比,基于任务和运动规划(TAMP)的系统首先计算高级任务计划,然后通过低级机器人控制(称为技能)实现这些计划。LLM的高级语言处理能力已经证明了解释指令并将它们分解成机器人动作步骤的能力,极大地推进了任务规划技术(Ni等人,2023年; Li等人,2023 b; Parakh等人,2023年; Wake等人,第2023条c款)。对于技能训练,一些研究已经探索了LLM/VLM用于设计奖励函数的用途(Yu等人,2023 a; Katara等人,2023年; Ma等人,2023年),生成数据以促进政策学习(Kumar等人,2023; Du等人,2023),或者作为奖励功能的一部分(Sontakke等人,2023年)的报告。与RL和IL等训练框架一起,这些努力将有助于开发高效的机器人控制器。
现场优化:由于意外和不可预测的环境条件,在机器人中执行长任务步骤可能会很困难。因此,在机器人领域的一个重大挑战涉及通过将任务计划与实时环境数据集成来动态地适应和改进机器人技能。例如,(Ahn等人,2022 b)提出了一种计算动作的可行性(即,示能)并将其与计划的任务进行比较。另外,存在关注于使LLM能够输出前置条件和后置条件的方法(例如,对象的状态和它们的相互关系)以优化它们的执行(Zhou等人,2023 c)并检测用于对任务计划进行必要修订的先决条件错误(拉曼等人,2023年)的报告。这些策略通过整合环境信息和在任务计划或控制器级别调整机器人的动作来寻求实现基于环境的机器人执行。
会话代理:在创建会话机器人时,LLM可以有助于与人类的自然的、上下文敏感的交互(Ye等人,2023 a; Wake等人,2023年f月)。这些模型处理并生成模仿人类对话的响应,使机器人能够参与有意义的对话。此外,LLM在概念性的评估中起着重要的作用(Hensel等人,2023年; Teshima等人,2022)和情感属性(Zhao等人,2023年; Yang等人,2023 b; Wake等人,2023d)。这些属性有助于理解人类意图和产生有意义的手势,从而有助于人-机器人通信的自然性和有效性。
导航代理:机器人导航的研究由来已久,主要集中在基于地图的路径规划和用于创建环境地图的同步定位与地图绘制(SLAM)等核心方面。这些功能已成为广泛使用的机器人中间件(如机器人操作系统(ROS))的标准(Guimarães等人,(2016年版)。
虽然经典的导航技术在许多机器人应用中仍然很流行,但它们通常依赖于静态或预先创建的地图。最近,人们对先进技术的兴趣越来越大,这些技术使机器人能够在更具挑战性的环境中导航,利用计算机视觉和自然语言处理等领域的突破。一个代表性的任务是对象导航(Chaplot等人,2020年a; Batra等人,2020年; Gervet等人,2023年; Ramakrishnan等人,2022; Zhang等人,2021),其中机器人使用对象名称而不是地图坐标进行导航,需要在环境中对对象名称进行视觉基础。此外,最近的注意力已经被给予在基础模型之上,在零发射的基础上,在完全不熟悉的新环境中导航机器人的技术,即所谓的零发射对象导航(Gadre等人,2023年; Dorbala等人,2023; Cai等人,2023年)的报告。另外,视觉语言导航(VLN)(安德森等人,2018 a)是一种代表性的任务,其中该任务涉及在以前看不见的真实世界环境中通过自然语言指令来导航代理(Shah等人,2023 a; Zhou等人,2023 a; Dorbala等人,2022; Liang等人,2023; Huang等人,第2023段b)。VLN会解译句子,而非物件名称,例如“go to bathroom on your left”。,因此它需要更高的功能来解析输入文本(Wang等人,(2019年版)。
基础模型的出现通过增强对人类语言指令的理解和对环境信息的视觉解释,促进了这种自适应、飞行中导航技术的发展。代表性VLN研究的更详细解释见6.2.2。
6.2.2 Experiments and Results
越来越多的证据表明,最近的VLMs和LLM在符号任务规划方面具有很好的能力(例如,要做什么)。然而,每个任务都需要低级别的控制策略(例如,如何做)来实现环境之间的成功交互。虽然强化学习和模仿学习是以数据驱动的方式学习策略的有前途的方法,但另一种有前途的方法是通过现场演示直接从人那里获得策略,这种方法称为从观察中学习(Wake等人,2021 a; Ikeuchi等人,0)的情况下。在本节中,我们介绍了一项研究,其中我们使用ChatGPT进行任务规划,并通过使用示能信息对其进行参数化来丰富计划,以促进有效和精确的执行(图13)。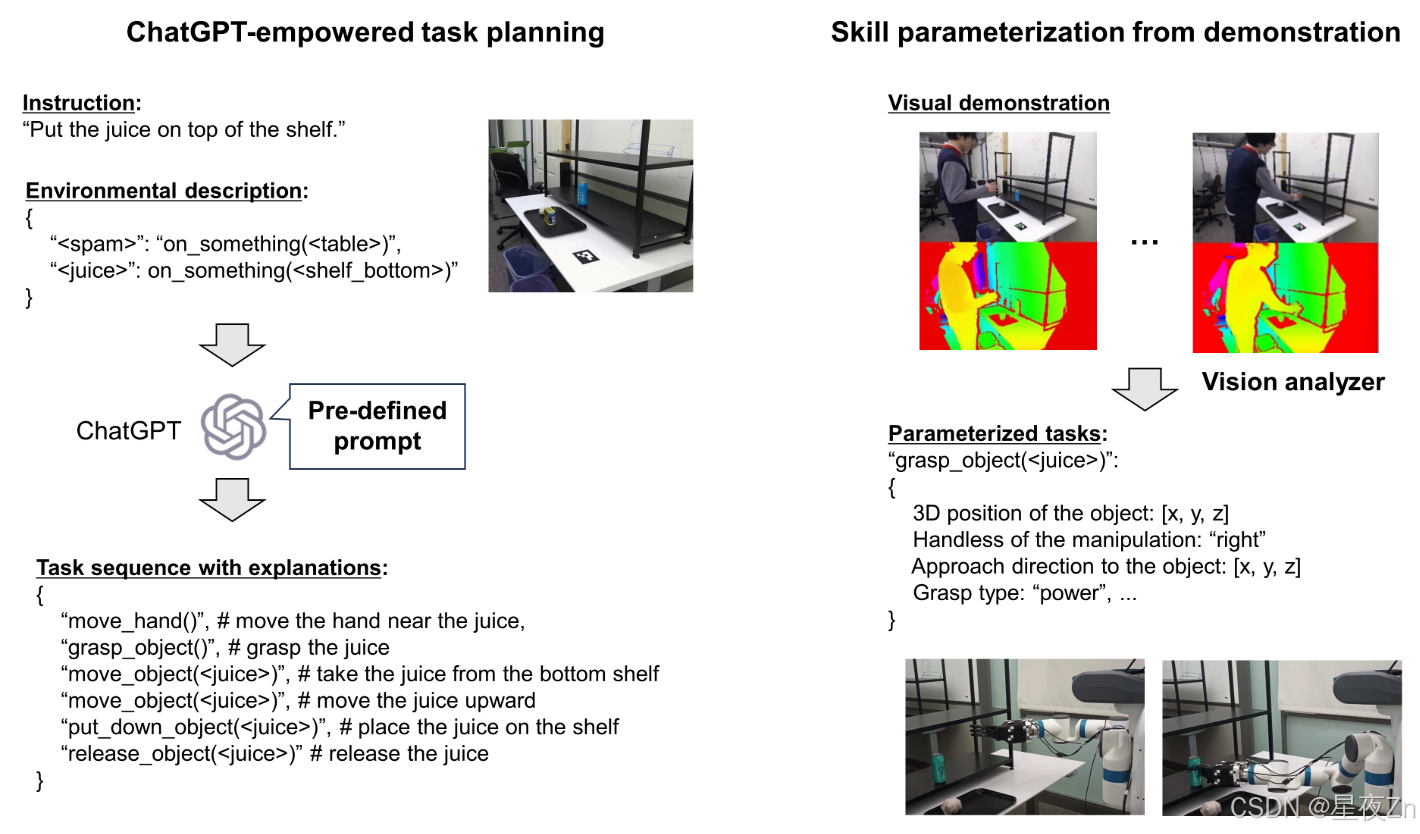
图13:集成ChatGPT授权任务规划器的机器人示教系统概述。该过程包括两个步骤:任务规划,其中用户使用任务规划器创建动作序列并根据需要通过反馈调整结果,以及演示,其中用户直观地演示动作序列以提供机器人操作所需的信息。视觉系统收集将用于机器人执行的视觉参数。
该管道由两个模块组成:任务规划和参数化。在任务规划中,系统被输入语言指令和工作环境的描述。这些指令沿着一组预定义的机器人动作和输出规范一起被编译成一个提供给ChatGPT的综合提示,然后生成一系列分解的任务及其文本描述(图13;左窗格)。值得注意的是,我们采用了一种少镜头的方法,这意味着ChatGPT没有针对此任务进行过培训,这在适用性方面具有优势,因为它消除了依赖于硬件的数据收集和模型培训的需要。此外,输出中的文本描述使用户能够根据需要检查和调整结果,这对于安全可靠的操作是至关重要的。图14示出了在VirtualHome(Puig等人,(2018年版)。实验结果表明,该方法具有较好的可行性。该方法具有较好的可操作性。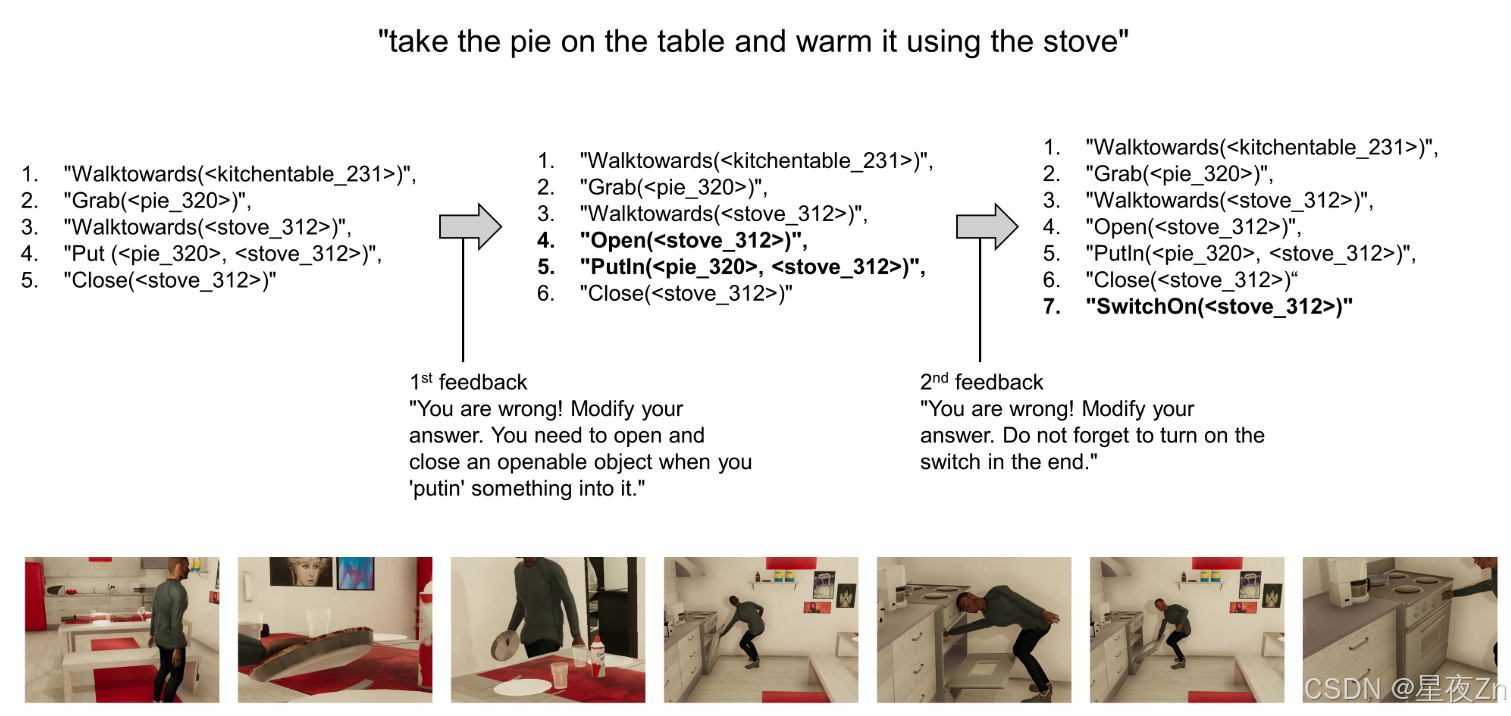
图14:通过自动生成的反馈调整输出序列的示例。我们使用开源模拟器VirtualHome进行实验。给出一个指令“把馅饼放在桌子上,用炉子加热。”任务规划器规划在VirtualHome中提供的功能序列。如果检测到执行中的错误,任务计划器将根据自动生成的错误消息更正其输出。
虽然任务规划器保证了任务序列之间的一致性,但实际上成功的操作需要详细的参数。例如,抓取类型对于在将内容物倒出的同时搬运容器是至关重要的,在模拟器中经常忽略这样的参数(参见图14抓取馅饼)。因此,在我们的机器人系统中,用户需要直观地演示每个动作(图13,右窗格)。这些任务具有执行所需的预定义参数,我们的视觉系统从视频中提取这些参数(Wake等人,2021年b月)。值得注意的是,我们的机器人系统不是为精确复制人类运动而设计的(即,遥控操作),而是处理变化的真实世界条件,诸如对象位置的变化。因此,从人类演示中提取的参数不包含精确的运动路径,而是包含指示有效的环境运动的示能信息(例如,用于避免碰撞的航路点(Wake等人,2023 a),抓握类型(Wake等人,2023 e)和上肢姿势(Sasabuchi等人,2021年; Wake等人,2021年a))。上肢的姿势在具有高自由度的机器人中是关键的,并且被设计为呈现与操作机器人共存的人的可预测姿势。赋予了示能的任务序列被转换成通过强化学习获得并由机器人执行的可重复使用的机器人技能序列(Takamatsu等人,2022年)的报告。
LLM支持的任务规划可以通过将其与VLM集成而扩展到更通用的机器人系统。在这里,我们展示了一个例子,我们使用GPT-4V(Vision)在多模态输入环境中扩展了上述任务规划器(图15),人类执行的动作旨在被机器人复制。本文仅显示部分提示。完整的提示可在microsoft.github.io/GPT4Vision-Robot-Manipulation-Prompts上找到。该管道获取演示视频和文本,然后输出一系列机器人动作。视觉分析器的目的是了解视频中人类所执行的动作。我们使用了GPT-4V,并提供了一个提示,以生成典型的人与人交流风格的文本指令。图16演示了如何使用文本输入允许用户对GPT-4V的识别结果进行反馈,以进行纠正。这种旨在提高识别结果的准确性的特征还使得能够进行更鲁棒的操作。
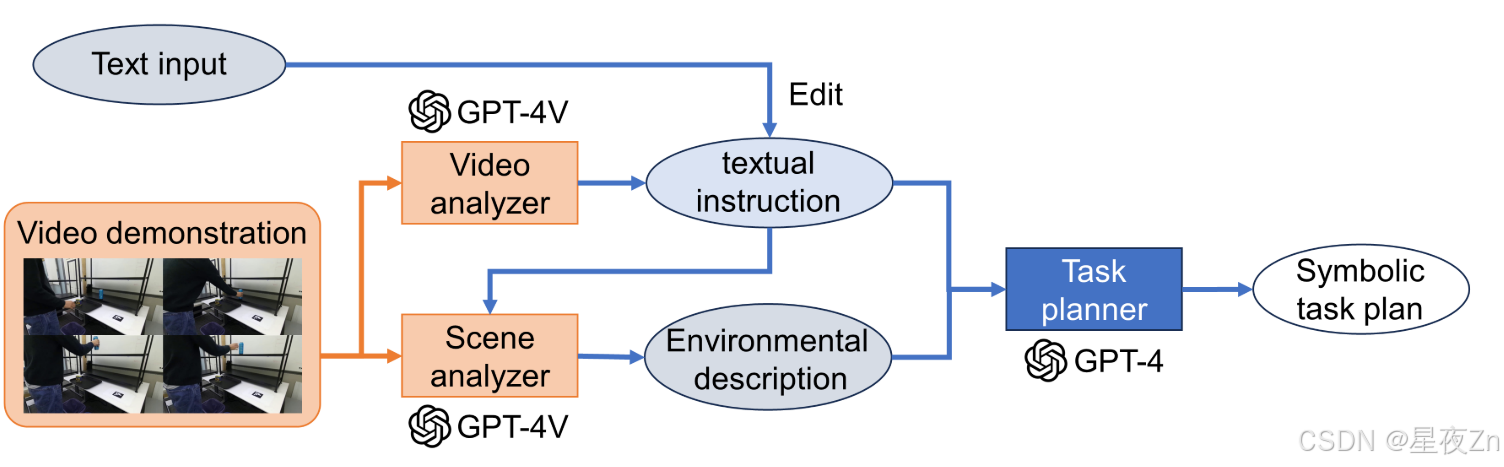
图15:利用GPT-4V和GPT-4的多模式任务规划器概述。该系统处理视频演示和文本指令,为机器人执行生成任务计划。

图16:视频分析仪的输出示例。这五个帧以固定的间隔提取并输入GPT-4V。我们在第6.2.2节中描述了整个管道。
接着,场景分析器基于指令和视频数据的第一帧(或环境的图像)将期望的工作环境编译成文本信息。该环境信息包括GPT-4V所识别的对象名称的列表、对象的可抓取属性以及对象之间的空间关系。虽然这些计算过程是GPT-4V内的黑盒,但信息是基于GPT-4V的知识和图像/文本输入输出的。图17显示了我们的场景分析器的示例输出。如图所示,GPT-4V成功地选择了与操作相关的对象。例如,当人在桌子上重新定位垃圾邮件容器时,在输出中包括该桌子,而对于冰箱打开任务忽略该桌子。这些结果表明,场景分析器对关于人的动作的场景信息进行编码。我们要求GPT-4V解释对象选择过程的结果以及这些选择背后的原因。在实践中,我们发现这种方法产生了合理的输出。最后,基于给定的文本指令和环境信息,任务规划器输出任务序列(Wake等人,第2023条c款)。

图17:利用GPT-4V的场景分析器的输出示例。我们在第6.2.2节中描述了我们的整个管道。
用于机器人导航的具身智能体。视觉语言导航(VLN)是指在真实的三维环境中,通过导航一个具体化的智能体来执行自然语言指令的任务。3D环境中的导航(Zhu等人,2017 a; Mirowski等人,2016年; Mousavian等人,2018年; Hemachandra等人,2015)是在物理世界中起作用的移动的智能系统的基本能力。在过去的几年中,大量的任务和评估协议(Savva等人,2017年; Kolve等人,2017年; Song等人,2017年; Xia等人,2018年;安德森等人,2018 a)已经提出,如(安德森等人,2018年b月)。VLN(安德森等人,2018 a)专注于真实的3D环境中基于语言的导航。为了解决VLN任务(安德森等人,2018 a)建立了基于注意的序列到序列基线模型。然后(Wang等人,2018)引入了一种混合方法,将无模型和基于模型的强化学习(RL)相结合,以提高模型的泛化能力。最后,(Fried等人,2018)提出了一种说话人跟随者模型,该模型采用数据增强、全景动作空间和VLN的改进波束搜索,在Room-to-Room数据集上建立了当前最先进的性能。扩展先前的工作,我们提出了一种用于VLN的增强型交叉模态匹配(RCM),(2019年版)。RCM模型是建立在(Fried等人,2018),但在许多重要方面不同:(1)RCM将新颖的多奖励RL与VLN的模仿学习相结合,而说话人-跟随者模型(Fried等人,2018)仅使用监督学习(安德森等人,2018年a)。(2)RCM推理导航器对单模态输入执行跨模态基础而不是时间注意机制。(3)RCM匹配评价器在结构设计上与Speaker相似,但前者用于为RL和SIL训练提供循环重构内在奖励,而后者用于为监督学习扩充训练数据。在(Wang等人,2019)中,我们研究了如何解决这一任务的三个关键领导板:跨模态接地,不适定反馈和泛化问题。如图18所示,我们提出了一种新的增强型跨模态匹配方法,该方法通过增强学习(RL)在局部和全局两个方面强制实施跨模态接地。特别地,匹配评论器用于提供内在奖励以鼓励指令和轨迹之间的全局匹配,并且推理导航器用于在局部视觉场景中执行跨模态接地。在VLN基准数据集上的测试结果表明,该RCM模型在SPL上的性能比以往的方法提高了10%,达到了最新的性能水平.为了提高学习策略的泛化能力,我们进一步引入了一种自监督模仿学习(Self-Supervised Imitation Learning,SIL)方法,通过模仿自己过去的好决策来探索未知环境。我们证明了SIL可以近似为一个更好和更有效的策略,它极大地减小了可见和不可见环境之间的成功率性能差距(从30.7%到11.7%)。此外,在(Wang等,2019)中,我们引入了一种用于探索的自监督模仿学习方法,以明确解决泛化问题,这是一个在先前工作中没有得到很好研究的问题。与该工作同时进行的是,(Thomason等人,2018年; Ke等人,2019年; Ma等人,2019 a,B)从多个方面研究了VLN任务,以及(Nguyen等人,2018年)引入了VLN任务的一个变体,在需要时通过请求语言帮助来查找对象。请注意,我们是第一个提出为VLN任务探索不可见环境的人。
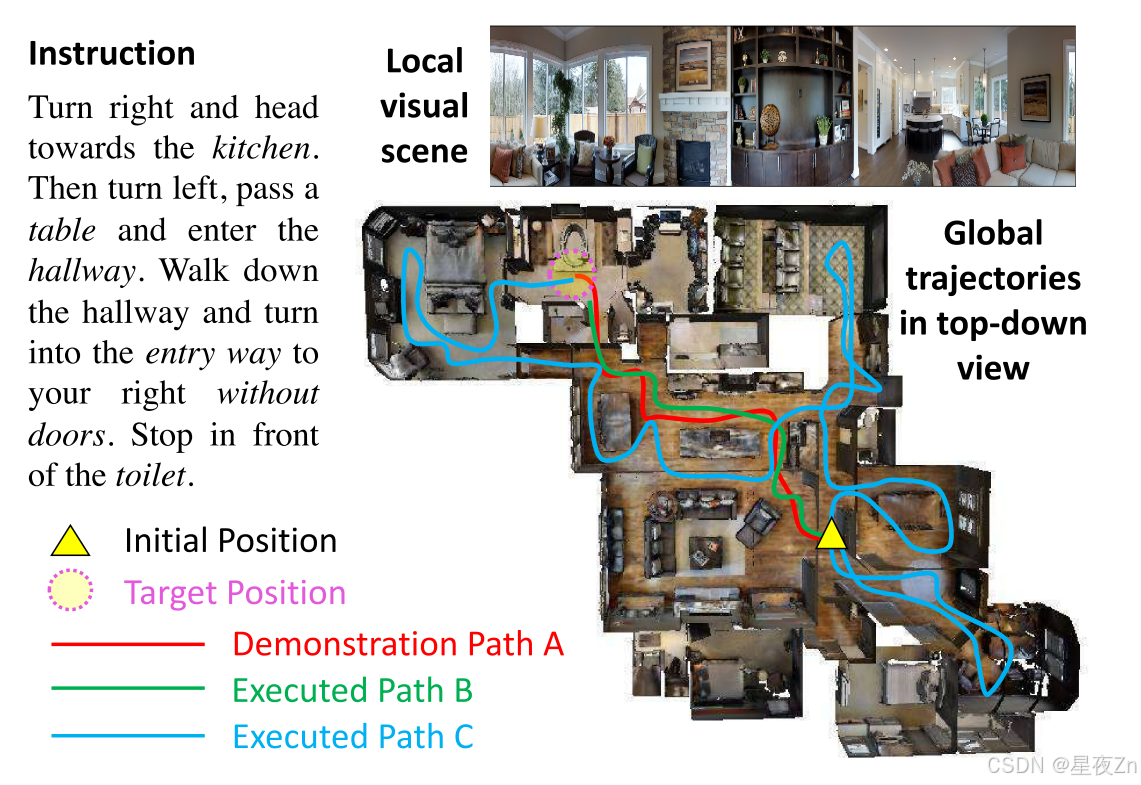
图18:用于VLN任务的具体化代理的示范(Wang等人,(2019年版)。以自顶向下的视图示出了指令、局部视觉场景和全局轨迹。座席无权访问自上而下视图。路径A是说明后面的演示路径。路径B和C是由代理执行的两个不同路径。
6.3 Healthcare
在医疗保健领域,LLM和VLM可以充当诊断试剂、患者护理助理,甚至是治疗辅助工具,但他们有着独特的领导层和责任。随着人工智能代理在改善患者护理和拯救生命方面的巨大潜力,同样危险的可能性是,它们的滥用或匆忙部署可能危及全球数千万人。我们讨论了在医疗保健背景下人工智能代理的一些有前途的路线,也讨论了一些关键的领导者面临的。
诊断智能体。由于对医学专家的高需求以及LLM帮助分类和诊断患者的潜力,使用LLM作为用于患者诊断的医学聊天机器人最近引起了极大的关注(Lee等人,2023年)的报告。对话代理,特别是那些能够有效地向来自不同患者人群的广泛人群传达重要医疗信息的代理,有可能为历史上处于不利地位或边缘化的群体提供公平的医疗保健服务。此外,世界各地的医生和医疗保健系统基本上负担过重,资源不足,导致全世界数亿人无法充分获得医疗保健(世界卫生组织和世界银行,2015年)。诊断试剂提供了一种特别有利的途径来改善数百万人的医疗保健,因为它们具有能够理解各种语言、文化和健康状况的能力。最初的结果已经表明可以通过利用大规模的网络数据来训练卫生保健知识的LMM(Li等人,2023年f月)。尽管这是一个令人兴奋的方向,但诊断试剂的前景并非没有风险。我们在下面的章节中强调了医学背景下幻觉的风险,以及解决方案的潜在途径。
知识检索代理。在医学背景下,模型幻觉是特别危险的,甚至可能导致严重的病人伤害或死亡,这取决于错误的严重程度。例如,如果病人错误地接受了一个诊断,表明他们没有实际患有的疾病,这可能会导致灾难性的后果。这包括延误或不适当的治疗,或者在某些情况下,完全缺乏必要的医疗干预。未诊断或误诊的严重疾病可能导致医疗费用增加,延长治疗时间,造成进一步的身体紧张,在极端情况下,严重伤害甚至死亡。因此,可以使用代理来更可靠地检索知识的方法(Peng等人,2023)或以基于检索方式生成文本(Guu等人,2020年)是很有希望的方向。将诊断代理与医学知识检索代理配对具有显著减少幻觉的潜力,同时提高诊断对话代理的响应的质量和精确性。
远程医疗和远程监控。基于代理的人工智能在远程医疗和远程监控领域也有很大的潜力,因为它可以改善医疗服务的可及性,改善医疗服务提供者和患者之间的沟通,提高效率并降低频繁医患互动的成本(Amjad等人,2023年)的报告。初级保健临床医生花费大量时间筛选患者消息、报告和电子邮件,而这些消息、报告和电子邮件通常与他们无关或不需要查看。支持代理可以帮助分类来自医生、患者和其他医疗保健提供者的消息,并帮助向各方突出重要消息,这一点具有很大的潜力。通过使代理人工智能系统能够与患者、临床医生和其他人工智能代理进行协调,远程医疗和数字健康行业将有巨大的潜力发生革命性变化。
6.3.1 Current Healthcare Capabilities
形象的理解。我们在图19中展示了现代多模式试剂(如GPT-4V)在医疗保健背景下的当前能力和局限性。我们可以看到,虽然GPT-4V拥有医院护理中涉及的设备和程序的重要内部知识,但它并不总是对用户提出的更多规定性或诊断性询问做出响应。

图19:在医疗图像理解领域内使用GPT-4V时的提示和响应示例。从左至右:(1)进行CT扫描的护士和医生的图像,(2)不规则EKG扫描的合成图像,以及(3)来自ISIC的图像(Codella等人,2018)皮肤病变数据集。我们可以看到,GPT-4V拥有重要的医学知识,能够对医学图像进行推理。但是,由于安全培训,无法对某些医学图像进行诊断。
视频理解。我们研究了两种背景下VLM Agent在医学视频理解中的性能。首先,我们研究了VLM代理在临床空间中识别重要患者护理活动的能力。其次,我们探讨了VLMs在更多技术视频(如超声)中的使用。具体而言,在图20中,我们展示了GPT-4V在医院护理和医疗视频分析方面的一些当前功能和局限性。
图20:在医疗保健视频理解领域使用GPT-4V时的提示和响应示例。我们将示例视频作为2x2网格输入,并覆盖指示帧顺序的文本。在前两个示例中,我们提示GPT-4V检查视频中的帧,以检测对志愿者患者进行的临床床边活动。对于最后一个示例,我们尝试提示GPT-4V评估超声心动图视频,但是由于GPT-4V的安全培训,它没有提供详细的响应。为清晰起见,我们将描述感兴趣活动的文本加粗,并将不必要的模型响应省略。我们把每个人的脸涂成灰色,以保护他们的隐私。
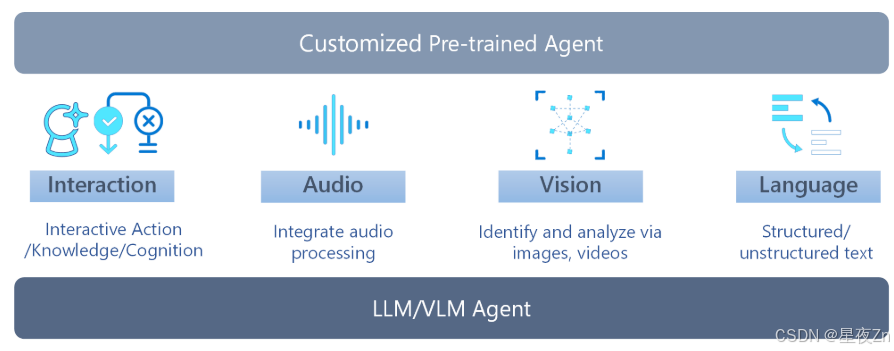
图21:交互式多模式代理包括四个主要支柱:交互,语音,视觉和语言。副驾驶代理由不同的服务组成。1)交互服务有助于为自动化操作、认知和决策提供统一的平台。2)音频服务将音频和语音处理集成到应用程序和服务中。3)视觉服务识别和分析图像、视频和数字墨水中的内容。4)语言服务从结构化和非结构化文本中提取意义。
6.4 Multimodal Agents
视觉和语言理解的整合对于开发复杂的多模态AI代理至关重要。这包括图像字幕、视觉问题回答、视频语言生成和视频理解等任务。我们的目标是深入研究这些视觉语言任务,探索它们在人工智能代理背景下的排行榜和机会。
6.4.1 Image-Language Understanding and Generation
图像-语言理解是一项涉及用语言解释给定图像中的视觉内容并生成相关语言描述的任务。这项任务对于开发能够以更人性化的方式与世界交互的人工智能代理至关重要。一些最流行的是图像字幕(Lin等人,2014年; Sharma等人,2018年; Young等人,2014年; Krishna等人,2016),参考表达(Yu等人,2016年; Karpathy等人,2014),以及视觉问答(Antol等人,2015年; Ren等人,2015年; Singh等人,(2019年版)。
最近,知识密集型可视问答任务,例如OKVQA(Marino等人,2019)、KBVQA(Wang等人,2015)、FVQA(Wang等人,2017)和WebQA(Chang等人,2021年)已经出台。多模态智能体应该能够识别图像中的物体,理解它们的空间关系,生成关于场景的精确描述语句,并利用推理技能来处理知识密集型视觉推理。这不仅需要物体识别能力,还需要对空间关系、视觉语义的深刻理解,以及将这些视觉元素映射到语言结构并整合世界知识的能力。
6.4.2 Video and Language Understanding and Generation
视频语言生成。视频字幕或视频故事讲述是为视频帧流生成连贯句子序列的任务。受在视频和语言任务中成功使用的递归大型基础模型的启发,Agent驱动的增强模型的变体在视频语言生成任务中显示出了有希望的结果。最根本的挑战在于,神经编码器-解码器模型的强大性能并不能很好地推广到视觉故事讲述,因为这项任务需要完全理解每幅图像的内容以及不同帧之间的关系。该领域的一个重要目标是创建一个能够有效地对帧序列进行编码并生成主题连贯的多句段落的Agent感知文本合成模型。
视频理解。视频理解将图像理解的范围扩展到动态视觉内容。这涉及对视频中的帧序列的解释和推理,通常与伴随的音频或文本信息结合。代理应能够与来自视觉、文本和音频模态的各种模态进行交互,以展示其对视频内容的高级理解。该领域中的任务包括视频字幕、视频问答和活动识别等。视频理解的领先者是多方面的。它们包括视觉和语言内容的时间对齐、长帧序列的处理,以及对随时间展开的复杂活动的解释。对于音频,代理可以处理口语、背景噪音、音乐和语音语调,以理解视频内容的情绪、设置和微妙之处。
先前的工作集中于使用在线可用的现有视频语言训练数据来建立视频基础模型(Li等人,2020年、2021 b; Fu等人,2022年;贝恩等人,2021年; Zellers等人,2021年、2022年; Fu等人,2023年)的报告。然而,由于这些数据集的有限且经常不一致的性质,支持这样的训练管道和功能是困难的。视频基础模型被设计为具有掩蔽和对比的预训练目标,并且随后在它们各自的任务上被调节。尽管在多模态基准测试中显示出显著的结果,但是这些模型在诸如动作识别之类的纯视频任务中遇到了困难,因为它们依赖于从噪声音频转录中构建的有限的视频文本数据。这一限制也导致缺乏大型语言模型通常具有的健壮性和细粒度推理技能。
其他方法,类似于那些用于图像语言理解的方法,利用强大的推理技能和对大型语言模型的广泛知识来改进视频解释的不同方面。视频理解的任务被语言模型(如ChatGPT和GPT 4)或图像语言模型(如GPT 4-V)简化,这些模型将音频、视频和语言模态视为单独的可解释输入数据类型,并将代理定位为强大的开源模型。例如,(Huang等人,2023 c; Li等,2023 g)通过使用开源视觉分类/检测/字幕模型对视频内容进行文本化,将视频理解转换为自然语言处理(NLP)问答公式化。(Lin例如,2023)将GPT 4-V与视觉、音频和语音方面的专用工具集成在一起,以促进复杂的视频理解任务,如在长格式视频中编写角色移动和动作的脚本。
并行研究探索了从大型模型生成缩放数据集,然后应用视觉指令调整(Liu等人,2023 c; Li等人,2023 c; Zhu等人,2023)上生成的数据。大量的音频、语音和视觉专家感知模型随后被用于对视频进行语言化。语音是用自动语音识别工具转录的,而视频描述和相关数据是用各种标记、基础和字幕模型产生的(Li等人,2023 g; Maaz等人,2023年; Chen等人,2023; Wang等人,2023年f月)。这些技术展示了如何在生成的数据集上对视频语言模型进行指令调整,从而增强视频推理和交流能力。
6.4.3 Experiments and Results
- 知识密集型模型:如INK中所介绍的(Park等人,2022年)和KAT(Gui等人,2022 a),一种结合了由人类注释的所需知识以支持知识密集型检索任务的密集型神经知识任务。
- 多模态智能体:人们对像Chameleon这样的多模态语言模型的兴趣越来越大(Lu等人,2023)和MM-React(Yang等人,第2023条c款)。
- 视觉指令调整:VCL(Gui等人,2022 b)、mini-GPT 4(Zhu等人,2023)、MPLUG-OWL(Ye等人,2023 b),LSKD(Park等人,2023 c)生成映像级指令调优数据集。
知识密集型代理。如图22和图23所示,在多模态机器学习中,基于知识的视觉问题回答和视觉语言检索任务是具有挑战性的任务,需要图像内容之外的外部知识。近年来,对大型变压器的研究主要集中在最大化模型参数存储信息的效率。这一系列研究探索了一个不同的方面:多模态变压器是否可以在其决策过程中使用显式知识。基于变换器的预训练方法在隐式学习多模态知识表示方面取得了显著的成功。然而,传统的方法,主要是单峰的,已经研究了知识检索和随后的答案预测,提出了关于检索到的知识的质量和相关性以及使用隐式和显式知识的推理过程的集成的问题。为了解决这些问题,我们引入了知识增强的Transformer(KAT),它在2022年的OK-VQA开放域多模态任务中的表现比其他人高出6%。KAT使用编码器-解码器结构将来自GPT 3的隐式知识与来自网站的显式知识相结合,并允许在答案生成期间使用这两种知识类型进行并发推理。此外,结合显式知识增强了模型预测的可解释性。代码和预训练模型可在https://github.com/guilk/KAT上获得。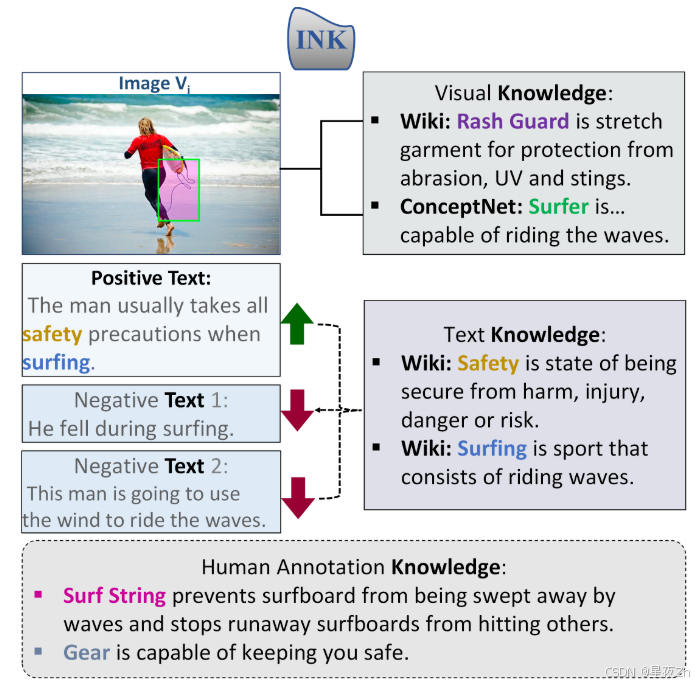
图22:强化神经知识(INK)的示例(Park等人,2022)任务,该任务使用知识从文本候选集合中识别与图像相关的文本。我们的任务涉及利用视觉和文本知识检索网络和人类注释的知识。
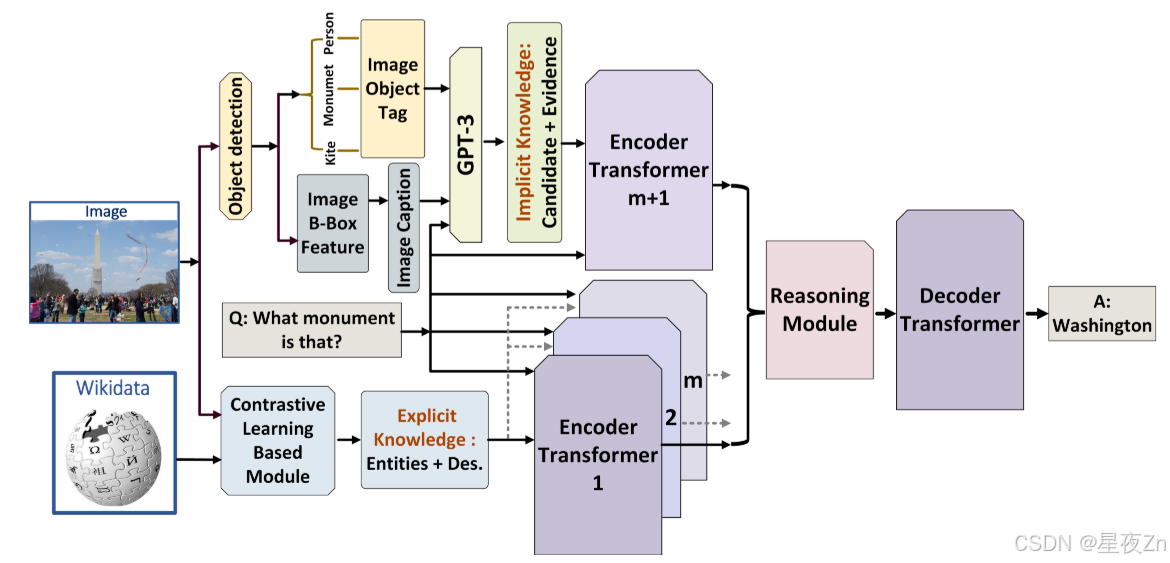
图23:KAT模型(Gui等人,2022 a)使用基于对比学习的模块从显式知识库检索知识条目,并使用GPT-3检索具有支持证据的隐式知识。知识的整合由相应的编码器Transformer处理,并与推理模块和解码器Transformer一起通过端到端训练来生成答案。
视觉语言Transformer Agent。接下来,我们介绍“从字幕训练视觉语言转换器”(VLC)模型(Gui等人,2022 b),一个Transformer,专门用图像-字幕对进行了预训练。尽管仅使用简单的线性投影层进行图像嵌入,但与依赖于对象检测器或监督CNN/ViT网络的其他方法相比,VLC在各种视觉语言任务中获得了有竞争力的结果。通过广泛的分析,我们探索的潜力VLC作为一个视觉语言的Transformer代理。例如,我们证明了VLC的视觉表示对于ImageNet-1 K分类非常有效,并且我们的可视化证实了VLC可以准确地将图像补丁与相应的文本标记进行匹配。更多训练数据的性能可扩展性突出了开发大规模,弱监督,开放域视觉语言模型的潜力。
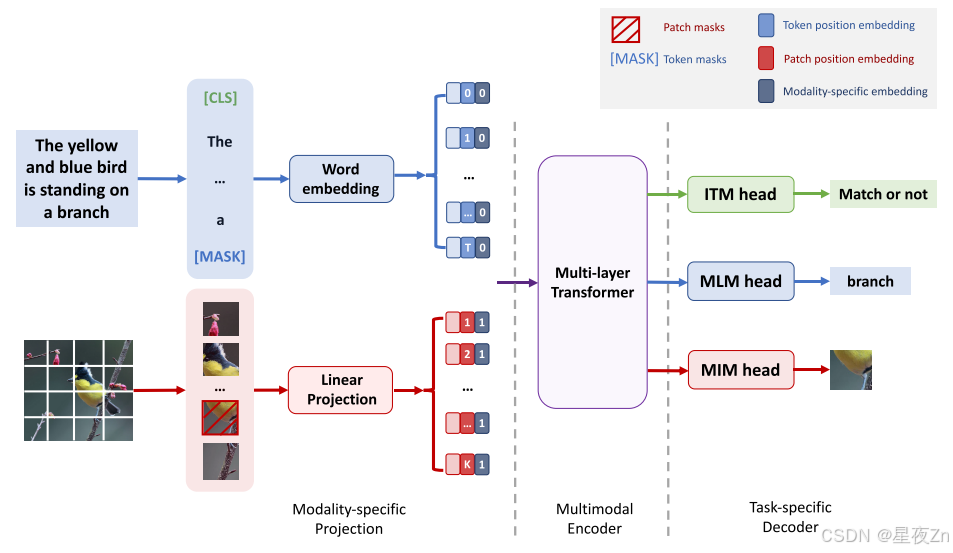
图24:VLC模型的整体架构(Gui等人,第2022条b款)。我们的模型包括三个模块:(1)模态特异性投射。我们使用简单的线性投影来嵌入拼接图像,并使用单词嵌入层来嵌入标记化文本;(2)多模态编码器。我们使用12层ViT(Dosovitskiy等,2021)从MAE(He等人,2022)(ImageNet-1 K,无标签)作为我们的主干;(3)特定任务解码器。我们通过仅在预训练期间使用的掩蔽图像/语言建模和图像-文本匹配来学习我们的多模态表示。我们使用一个2层MLP来微调我们的多模式编码器,以执行下游任务。重要的是,我们发现掩蔽图像建模目标在整个第二阶段预训练中是重要的,而不仅仅是对于视觉Transformer的初始化。
6.5 Video-language Experiments
为了理解转换预先训练的图像-LLM以用于视频理解的实用性,我们在时间上扩展并微调InstructBLIP(Dai等人,2023)用于视频字幕。具体地说,我们扩展了InstructBLIP的视觉编码器(EVA-CLIP-G(Sun等人,2023 b))使用与FrozeninTime(时间冻结)相同的划分的空间-时间注意方案(Bain等人,2021)并保持Q-形成器和LLM(Flan-T5-XL(Chung等人,2022年),在训练期间被冻结。我们冻结视觉编码器的所有空间层,同时在字幕训练期间保持时间层不冻结。这使得我们的模型可以将图像和视频作为输入(与InstructBLIP的图像级性能相匹配)。我们在WebVid 10 M的500万个视频字幕子集上训练(Bain等人,2021年)的报告。我们在图25中看到了两个输出示例。然而,现有的代理不能完全理解视频内容中的精确的、细粒度的视觉细节。视觉指令调整方法也有类似的局限性,它们缺乏一般的、人类水平的感知能力,而这一点仍有待于多模态模型和代理来解决。
图25中,指令调整模型在准确总结视频中的可见动作和有效识别“坐在长椅上的人”等动作方面显示出了希望。然而,他们有时会添加不正确的细节,如“人对着镜头微笑”,揭示了在捕捉谈话主题或视频氛围方面的不足,这些元素对人类观察者来说是显而易见的。这一不足突出了另一个关键的限制:省略了音频和语音模式,这将丰富对视频的上下文理解,有助于更准确地解释和防止这种误传。弥合这一差距需要全面整合现有模式,使多式联运代理人能够达到与人类感知相似的理解水平,并确保对视频口译采取完全多式联运的做法。

图25:使用视频微调的InstructBLIP变体时的示例提示和响应(方法在第6.5节中描述)。我们的模型能够产生描述场景的长文本响应,并能够回答与视频中事件的时间性相关的问题。
具有GPT-4V的音频视频语言代理。然后,我们评估GPT-4V作为多模式试剂的能力,其整合了视觉、音频和语音,用于对视频的细微差别和精确理解,遵循在(Lin等人,2023年)的报告。图26所示的结果比较了各种视频代理在视频摘要任务上的性能。视频指令调谐模型(Li等人,2023 g)提供了准确的内容,但缺乏全面性和细节,缺少具体的行动,如有条不紊地使用扫帚测量树的高度。
为了提高视频描述的准确性,我们使用GPT-4V来为帧添加字幕,而音频及其转录则来自OpenAI Whisper模型。然后,我们提示GPT-4V只使用帧标题创建视频摘要,然后使用帧标题和音频转录。最初,我们观察到,帧标题本身可以导致虚构的事件,如一个人咬下一根棍子在第三段。这些不准确之处仍然存在于视频摘要中,描述如“在一个好玩的扭曲中,他在水平拿着它的同时咬下它。“如果没有音频输入,工程师将无法更正这些字幕错误,从而导致描述在语义上是正确的,但在视觉上会产生误导。
然而,当我们向代理提供音频转录时,它设法准确地描述了内容,甚至捕捉到了详细的物理动作,如“将扫帚柄垂直于身体并将其向下旋转。“这种程度的细节是显着更多的信息,让观众更清楚地了解视频的目的和关键细节。这些发现强调了整合音频,视频和语言交互以开发高质量多模态代理的重要性。GPT-4V作为这种高级多模态理解和相互作用的有希望的基础出现。
图26:第6.5节中描述的音频多模态代理。幻觉内容以红色突出显示。我们使用GPT-4V生成1)带有视频帧的视频聊天摘要; 2)带有帧标题的视频摘要; 3)带有帧标题和音频信息的视频摘要。
Embodied Multi-modal Agents with GPT-4V。如图27所示,我们主要使用StackOverflow获取初始Question,然后使用“Bing search”API检索与问题对应的相关视频和音频。接下来,我们主要使用GPT-4V来获取相关的文本信息和高层视频描述。另一方面,我们通过ASR将关键帧音频转换为关键帧的低级段描述。最后,我们使用GPT-4V生成令人信服的“幻觉”,作为视频问答任务的硬否定查询。我们支持视频当前帧中的交互和问答,以及整体高级视频描述的摘要。在推理过程中,我们还通过网络搜索结合联合收割机的外部知识信息,以提高回答能力。
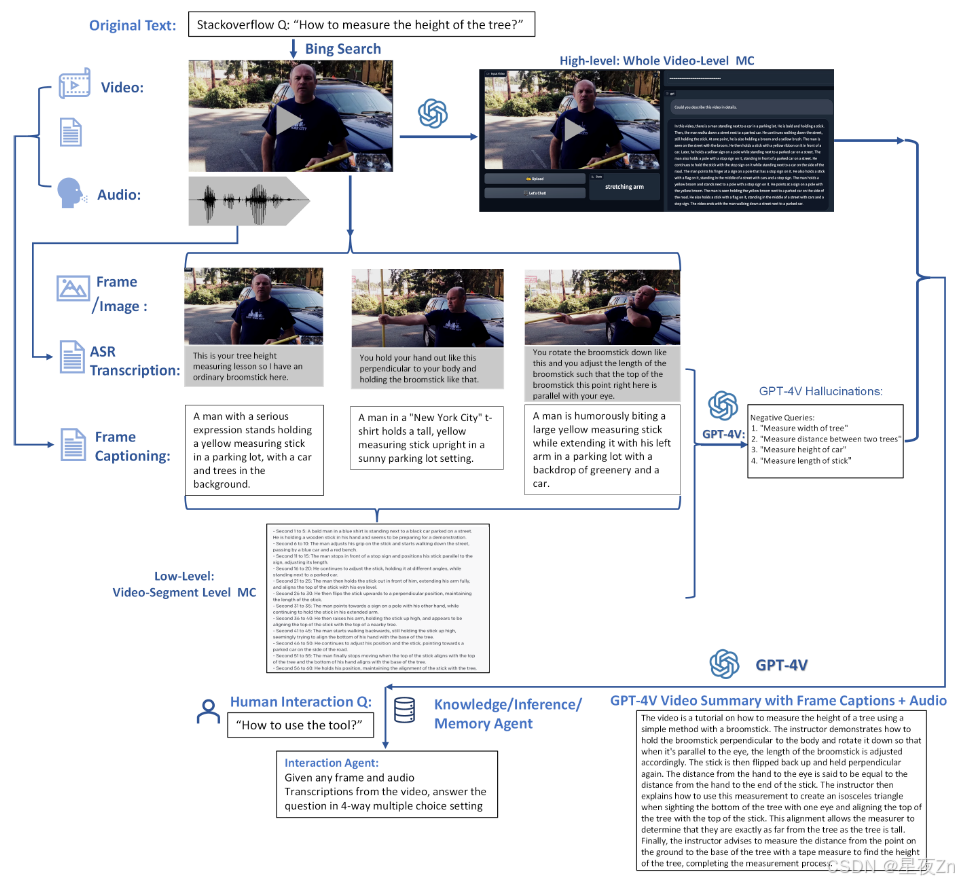
图27:一个交互式多模态代理,它结合了视觉、音频和文本模态,用于视频理解。我们的管道挖掘了很难的负面幻觉,为VideoAnalytica挑战产生了困难的查询。交互式音频-视频-语言代理数据集的更多相关细节在第9.2节中描述。
GPT-4V的主要提示信息如下。为了清晰起见,整个提示符都是缩进的;它超过一页长。
GPT-4V是一个助手,为那些能听到但看不见的视障人士提供视频中的描述性、信息性和全面的细节。工作是通过合成给定的注释并将其输出为JSON来创建高质量,密集的视频描述。具体而言,GPT-4V将被给予用于搜索视频的原始查询、视频标题、描述、音频转录以及视频中特定时间的潜在噪声描述。同一视频的不同片段被注释为“[时间开始-时间结束(以秒为单位)]”文本““。利用transmittance和描述一起来推理视频中可能发生的确切细节和视觉演示。GPT-4V将根据需要对时间戳进行联合收割机组合或分段,以提供视频的最佳分段。
对GPT-4V输出的期望:
1.面向对象的描述:优先考虑音频暗示的合理动作,运动和物理演示,用动态视觉线索丰富你的叙述。
2.完整的视频覆盖:提供持续一致的音频描述体验,涵盖视频持续时间的每一刻,确保没有内容未被描述。
3.简明细分:用1-2句话的集中、简洁的片段来构建你的描述,以有效地传达视觉动作,而不需要压倒性的细节。
4.情境视听合成:将口头音频内容与推断的视觉元素无缝地混合,以形成反映潜在的活动的叙述。
5.富有想象力和合理的推测:在你的描述中注入与音频相对应的创造性但可信的视觉细节,增强场景理解。
6.准确的时间码对应:将你的描述片段与相应的时间码对齐,确保推测性的视觉细节与音频叙事的时间轴同步。
7.自信的叙述交付:保证描述,就像推测的视觉效果正在发生一样,给听众灌输信心。
8.省略令人难以置信的细节:对不合理地符合所提供的音频和视频信息所建立的背景的对象或事件的描述。
最终的输出应该以JSON格式进行结构化,包含一个字典列表,每个字典详细描述视频的一个片段。
最终的输出应该以JSON格式进行结构化,包含一个字典列表,每个字典详细描述视频的一个片段。
[ ‘start’: <start-time-in-seconds>, ‘end’: <end-time-in-seconds>, ‘text’: “<Your detailed single-sentence, audio-visual description here>" ]
对于MC创建:我们的任务是为视频到文本检索任务创建多项选择题,通过查看标题和通过音频传输进行阅读来简单地解决这些问题。为此,我们将获得原始查询以获取视频,描述,音频转录以及视频中特定时间的潜在噪声描述。
- Format ofaudio transcription: -[start-end time in seconds] “transcription"
- Format ofnoisy description: - [time in seconds] “description"
我们请GPT-4V生成四个查询,其中主要查询与视频内容一致,其他三个否定与我们的主要查询略有不同。选择主要查询不应仅涉及收听音频transmittance,例如,文本原始查询包含在音频transmittance中。底片应与视频内容密切相关,但不完全一致,需要对视频进行视觉理解以区分。例如,以微妙的方式修改语义,以便人们需要观看视频而不仅仅是收听以选择原始查询。用标题式语句编译四个查询,第一个查询是改写后的原始查询。
一步一步地思考如何使用视频中的信息提出负面陈述。并证明负面的质疑是不正确的,但仍然是令人信服的选择,需要细致入微的理解视频。以及人类如何不会意外地选择否定词而不是原始查询。
最后,我们提出了以下格式的分析和4个问题的工作。无需生成您如何翻译原始查询。
- Video Analysis: xxx
- Queries: [query1, query2, query3, query4]
- Justification: xxx
6.6 Agent for NLP
6.6.1 LLM agent
几十年来,识别任务指令并采取行动一直是交互式人工智能和自然语言处理领域的一个基本挑战。随着深度学习技术的发展,人们越来越有兴趣联合研究这些领域,以改善人-智能体协作。我们确定了三个具体的方向,以改善语言为基础的代理:
- 工具使用和知识库查询。该方向强调了将外部知识库、网络搜索或其他有用工具集成到人工智能代理的推理过程中的重要性。通过利用来自各种来源的结构化和非结构化数据,代理可以增强其理解并提供更准确和上下文感知的响应。此外,它还能培养座席在遇到不熟悉的情况或查询时主动寻找信息的能力,从而确保做出更全面、更明智的响应。实例包括Toolformer(Schick等人,2023)和检索所需内容(Wang等人,2023克)。
- 改进代理推理和计划。提高智能体的推理和规划能力是有效的人-智能体协作的关键。这涉及到开发能够理解复杂指令、推断用户意图和预测潜在未来场景的模型。这可以通过要求代理反思过去的动作和失败来完成,如ReAct(Yao等人,2023 a),或者通过将代理人的思维过程构造为搜索的形式(Yao等人,第2023段b)。通过模拟不同的结果并评估各种行动的后果,代理可以做出更明智的上下文感知决策。·将系统和人的反馈结合起来。人工智能代理通常可以在两种主要环境中工作:一种是提供关于其行为有效性的明确信号的环境(系统反馈),另一种是与能够提供口头批评的人类合作的环境(人类反馈)。该方向强调了对自适应学习机制的需要,该机制允许代理改进它们的策略并纠正错误,例如在AutoGen中(Wu等人,2023年)的报告。不断从各种反馈源中学习和调整的能力确保了代理始终能够为用户提供帮助并满足用户需求。
6.6.2 General LLM agent
几十年来,识别和理解智能体内容和自然语言一直是交互式人工智能和自然语言处理领域的一个基本挑战。随着深度学习技术的发展,人们越来越有兴趣将这两个领域结合起来研究,以深入理解智能体规划或用于知识推理和自然语言生成的人类反馈。这些是许多人机交互代理的关键组件,例如“AutoGen”(Wu等人,2023)和“检索您所需的内容”(Wang等人,2023g)。
6.6.3 Instruction-following LLM agents
此外,创建可以被训练为有效地遵循人类指令的LLM代理已经成为一个重要的研究领域。最初的模型使用人类反馈来训练代理报酬模型以模拟人类偏好,这是通过被称为具有人类反馈的强化学习(RLHF)的过程(Ouyang等人,2022年)的报告。这一过程产生了诸如InstructGPT和ChatGPT的模型。为了更有效地训练遵循指令的LLM代理而不需要人的标签,研究人员开发了一种更有效的用于指令调整的方法,该方法直接在指令/响应对上训练LLM代理,该指令/响应对由人如Dolly 2.0生成,或者从LLM如Alpaca自动生成(Taori等人,2023年)的报告。我们在图28中展示了整个羊驼训练流程。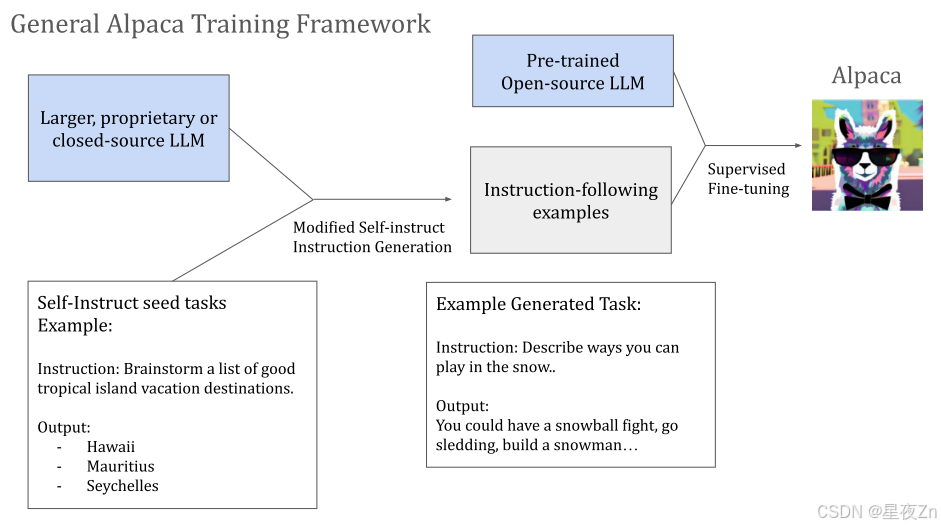
图28:用于训练羊驼模型的训练配方(Taori等人,2023年)的报告。在较高的级别,现有的LLM用于从较小的种子任务集生成较大的指令遵循示例池。所生成的遵循指令的示例然后被用于在底层模型权重可用的情况下对LLM进行指令调优。
6.6.4 Experiments and Results
尽管对话和自我反馈系统的采用越来越多,但这些形式的人工智能仍然不能很好地从它们自己的隐性知识中产生事实上正确的反应,因此经常在推理时使用外部工具,如网络搜索和知识检索机制,以增加它们的反应。解决这一问题将有助于在许多实际应用中为用户创造更吸引人的体验。在社交对话中(如Instagram和Facebook等社交媒体平台上的对话),或在问答网站(如Ask或Quora)上,人们通常通过一系列评论和网络搜索与讨论相关的信息和知识来与他人互动。因此,在该上下文中生成会话转向的任务不是简单地在传统的NLP模型和任务上引导,而是使用代理通过反映知识搜索和获取的智能行为来生成对话(Peng等人,2023年)的报告。通过这种方式,NLP任务的智能代理扩展了任务描述,并通过在对话期间添加显式知识搜索和检索步骤来改进响应的可解释性。将这些web搜索和检索代理作为对话期间的反馈并入将有助于参与人与代理之间的进一步和更深的社会交互(Wang等人,2023年e月)。如图29所示,我们为Transformer语言模型引入了一种新的建模范式,该范式从输入文本中检测和提取重要的逻辑结构和信息,然后通过精心设计的多层分层逻辑投影将它们集成到输入嵌入中,从而将逻辑结构注入到预先训练的语言模型中,作为一种NLP代理。(Wang例如,2023e)提出了一种通过逻辑检测、逻辑映射和分层逻辑投影的组合来构造用于Transformer语言模型的逻辑感知输入嵌入的新颖方法,然后开发了相应的新建模范例,该范例可以将所有现有的Transformer语言模型升级为逻辑转换器,以一致地提高它们的性能。通过对文本逻辑结构的深入理解,所提出的逻辑Transformer代理与其基准Transformer模型相比,始终具有上级的性能.对于人类用户来说,对于通过对话和信息检索之间的基于代理的协调来传递有意义和有趣的对话来说,这些方面通常是更重要的。深入研究自然语言处理,本主题将讨论的进展和领先的董事会,使LLMs更积极,更适合各种语言为中心的任务。
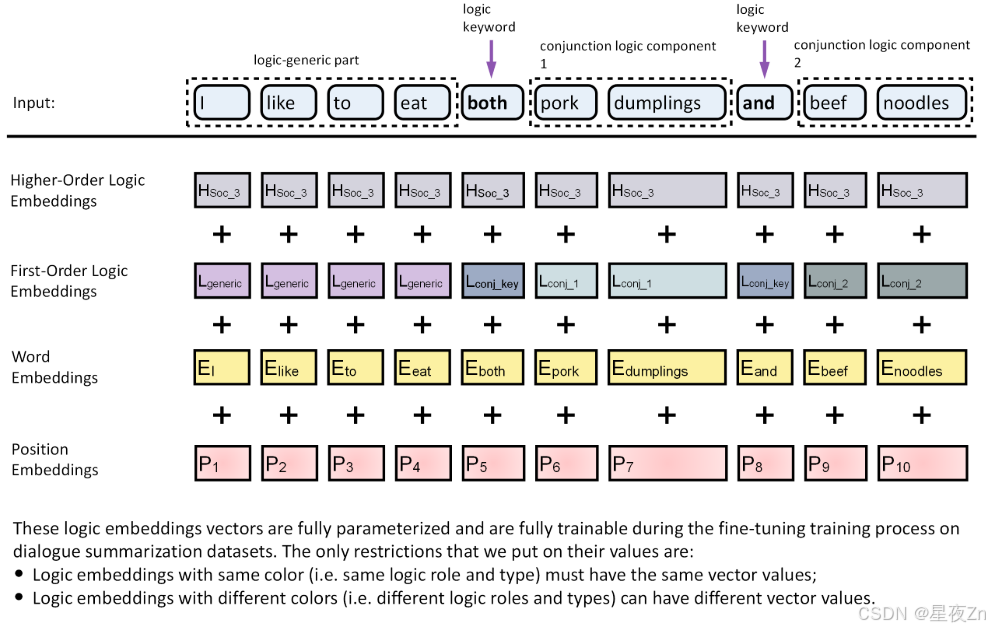
图29:逻辑Transformer代理模型(Wang等人,2023年e月)。在基于转换器的抽象文摘模型中加入逻辑推理模块,赋予逻辑Agent对文本和对话逻辑进行推理的能力,从而生成质量更好的抽象文摘,减少真实性错误。
开放领域问答(QA)系统通常遵循检索然后阅读的范式,其中检索器用于从大型语料库中检索相关段落,然后读者根据检索到的段落和原始问题生成答案。在(Wang等人,2023 g),我们提出了一个简单而新颖的相互学习框架,通过一个名为知识选择器代理的中间模块来提高检索然后阅读风格模型的性能,我们用强化学习来训练它。细粒度的知识选择器到检索,然后读者范式,其目标是建立一个小的子集的段落保留问题相关的信息。如图30所示,知识选择器代理被训练为我们的新的相互学习框架的一个组件,该框架迭代地训练知识选择器和阅读器。我们采用了一种简单而新颖的方法,采用政策梯度来优化知识选择器agnet,使用读者的反馈来训练它选择一个小的和翔实的段落集。这种方法避免了暴力搜索或手动设计的查询,而不需要任何带注释的查询-文档对进行监督。我们表明,迭代训练读者和知识选择器代理可以在一些公共开放域问答基准测试中获得更好的预测性能。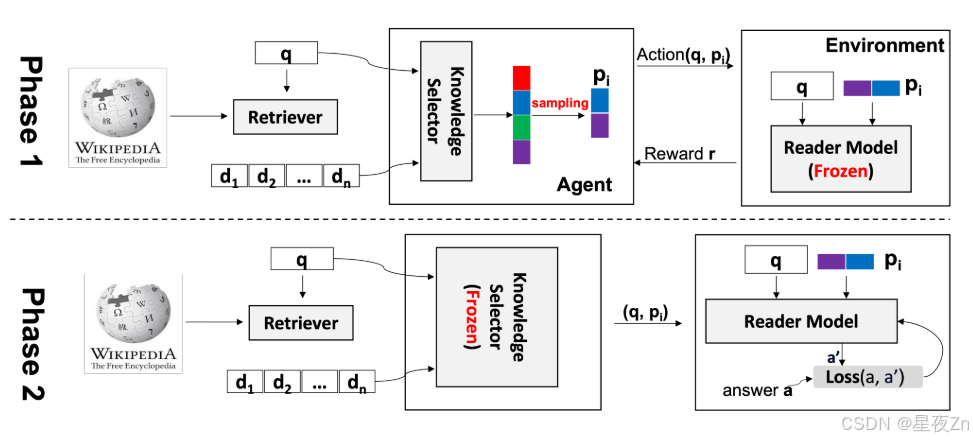
图30:一个提出的NLP代理的架构(Wang et al.,2023g)相互学习框架。在每个时期,阶段1和阶段2交替执行。在阶段1期间,读者模型的参数保持固定,并且仅更新知识选择器的权重。相反,在阶段2期间,读者模型的参数被调整,而知识选择器的权重保持冻结。
7 Agent AI Across Modalities, Domains, and Realities
7.1 Agents for Cross-modal Understanding
由于缺乏包含视觉、语言和智能体行为的大规模数据集,多模态理解是创建通才人工智能智能体的一个重大挑战。更一般地,用于AI代理的训练数据通常是模态特定的。这导致大多数现代多模态系统使用冻结子模块的组合。一些显著的例子是火烈鸟(Alayrac等人,2022)、BLIP-2(Li等人,2023 c)和LLaVA(Liu等人,2023 c),所有这些都利用了冻结LLM和冻结视觉编码器。这些子模块在单独的数据集上单独训练,然后训练自适应层以将视觉编码器编码到LLM嵌入空间中。为了在AI代理的跨模态理解方面取得更大进展,使用冻结LLM和视觉编码器的策略可能需要改变。实际上,当为机器人和视觉语言任务联合调整视觉编码器和LLM时,能够在机器人领域内采取动作的最新视觉语言模型RT-2显示出显著改进的性能(Brohan等人,2023年)的报告。
7.2 Agents for Cross-domain Understanding
创建通才代理的一个关键挑战是不同领域的独特视觉外观和不同的动作空间。人类拥有解释来自各种来源的图像和视频的能力,包括真实的世界,视频游戏和专业领域,如机器人和医疗保健,一旦他们熟悉这些领域的具体细节。然而,现有的LLM和VLM通常在它们训练的数据和它们应用的不同领域之间表现出显着差异。值得注意的是,当试图开发一个可以有效学习跨域多个控制系统的单一策略时,训练代理模型来预测特定的动作是一个相当大的挑战。一般来说,大多数现代作品在特定领域应用系统时采取的方法是从预先训练的基础模型开始,然后为每个特定领域微调单独的模型。这无法捕获域之间的任何共性,并导致用于训练的数据集更小,而不是利用每个域的数据。
7.3 Interactive agent for cross-modality and cross-reality
开发能够成功地理解和执行不同现实中的任务的AI代理是一个持续的挑战,第2023条a款)。特别是,由于真实世界和虚拟现实环境的视觉差异和环境物理分离,对智能体同时理解它们是具有挑战性的。在跨现实环境中,当对真实世界数据使用模拟训练策略时,模拟到真实的转换是一个特别重要的问题,我们将在下一节中讨论。
7.4 Sim to Real Transfer
使在仿真中训练的模型能够部署在真实的世界中的技术。具体化Agent,尤其是基于RL策略的Agent,通常在模拟环境中训练。这些模拟并不完全复制真实的世界的特征(例如,干扰、光、重力和其它物理性质)。由于模拟和现实之间的这种差异,在模拟中训练的模型在应用于真实的世界时往往难以表现良好。这个问题被称为“模拟到真实的”问题。为了解决这个问题,可以采取几种方法:
- 域随机化:域随机化是一种训练模型同时在仿真环境内随机改变参数的技术(例如,物体外观、传感器噪声和光学特性)来预测真实的世界的不确定性和变化(Tobin等人,(2017年版)。例如,在训练基于RL的抓取技能的上下文中,在物体形状中引入随机性可以导致能够适应具有稍微不同形状的物体的策略(Saito等人,2022年)的报告。
- 领域适应性:域自适应或域转移是一种通过用大量模拟图像和较小的真实世界图像集训练模型来弥合模拟域和真实世界域之间的差距的技术。在实际设置中,不成对的图像到图像转换方法,例如CycleGAN(Zhu等人,2017 b)是由于难以准备跨域的成对图像。存在用于强化学习的几个增强版本,包括RL-CycleGAN(Rao等人,2020),以及用于模仿学习的,例如RetinaGAN(Ho等人,2021年)的报告。
- 仿真的改进:真实感仿真是拟真实的转换的关键。这种努力的一部分是通过系统识别技术实现的(Zhu等人,2017年c; Allevato等人,2020),其目的是识别模拟参数以模拟真实世界环境。此外,使用真实感模拟器在基于图像的强化学习中将是有效的(Martinez-Gonzalez等人,2020年; Müller等人,2018; Shah等人,2018年; Sasabuchi等人,2023年)的报告。
模拟到真实的转移仍然是一个中心的挑战,在研究的模拟代理,方法不断发展。理论和实证研究对于进一步推进这些技术至关重要。
8 Continuous and Self-improvement for Agent AI
当前,基于基础模型的人工智能代理具有从多个不同数据源学习的能力,这允许用于训练的数据的更灵活的源。这样做的两个关键结果是(1)可以使用用户和基于人的交互数据来进一步细化和改进代理,以及(2)可以使用现有的基础模型和模型工件来生成训练数据。我们将在下面的章节中更详细地讨论每一个问题,但是我们注意到,由于当前的人工智能代理在很大程度上依赖于现有的预先训练的基础模型,因此它们通常不会从与环境的持续交互中学习。我们认为这是一个令人兴奋的未来方向,Bousmalis等人的初步工作表明,用于机器人控制的自我改进代理能够在没有监督的情况下通过环境交互作用不断学习和改进(Bousmalis等人,2023年)的报告。
8.1 Human-based Interaction Data
使用基于人类的交互数据背后的核心思想是利用大量的Agent-人类交互来训练和改进Agent的未来迭代。有几种策略用于从人-代理交互中改进代理。
- 额外的训练数据也许人类-代理交互的最简单用法是使用交互示例本身作为代理未来迭代的训练数据。这通常需要过滤策略来区分成功的代理示例和不成功的交互示例。过滤可以是基于规则的(例如,达到某个期望的最终目标状态),基于模型的(例如,分类成功对不成功的交互),或者在事后检查和/或修改交互示例之后手动选择。
- 在与用户交互的过程中,代理系统可以提示用户几个不同的模型输出,并允许用户选择最佳输出。这通常由像ChatGPT和GPT-4这样的LLM使用,用户可以从中选择一个最符合其偏好的输出(从几个输出中选择一个)。
- 安全培训(红队)Agent AI背景下的红队指的是拥有一个专门的对手团队(人或计算机),他们试图利用和暴露Agent AI系统中的弱点和漏洞。尽管本质上是对抗性的,但红队通常被用作了解如何改进AI安全措施和减少有害输出发生的一种手段。核心原则是发现诱导不需要的代理输出的一致方法,以便可以在明确纠正这种行为的数据上训练模型。
8.2 Foundation Model Generated Data
随着学术界和工业界产生的强大的基础模型工件的出现,已经开发了各种方法来使用各种提示和数据配对技术从这些工件中提取和生成有意义的训练数据。
- LLM指令调整用于从LLM生成指令遵循训练数据的方法已经允许基于较大的专有LLM的输出对较小的开源模型进行微调(Wang等人,第2022条b款)。例如,羊驼(Taori等人,2023)和小羊驼(Zheng等人,2023)是基于开源LLaMA家族的LLM(Touvron等人,2023),已经在ChatGPT和人类参与者的各种输出上进行了调整。这种指令调整的方法可以被看作是一种知识提炼的形式,其中较大的LLM用作较小的学生模型的教师模型。重要的是,尽管LLM指令调整已经被证明将教师模型的写作风格和一些指令遵循能力转移到学生模型,但是在教师和学生模型的真实性和能力之间仍然存在显著的差距(Gudibande等人,2023年)的报告。
- 视觉-语言对最近的一些研究试图通过自动生成视觉内容的字幕和其他文本来增加视觉-语言模型可用的预训练数据的多样性。例如,LLaVA(Liu等,2023 c)使用了150,000个来自主要由LLM生成的文本和视觉输入的指令遵循行为的示例。其他工作已经表明使用VLM来重新标注图像可以改善训练数据和图像生成模型的后续质量(Segalis等人,2023年)的报告。在视频理解的领域内,使用VLM和LLM来重新捕获视频已经被示出改进了在重新捕获的视频上训练的后续VLM的性能和质量(Wang等人,2023 f; Zhao等人,2022年)的报告。
9 Agent Dataset and Leaderboard
为了加速这一领域的研究,我们提出了两个基准分别为多智能体游戏和代理视觉语言任务。我们将发布两个新的数据集-“CuisineWorld”和“VideoAnalytica”-以及一组基线模型,鼓励参与者探索新的模型,系统,并在我们的排行榜测试集上提交他们的结果。
9.1 “CuisineWorld” Dataset for Multi-agent Gaming
CuisineWorld是一款基于文本的游戏,让人想起Overcooked!它为AI驱动的代理提供了一个合作和协同游戏的平台。该数据集将测试多智能体系统的协作效率,深入了解LLM和其他系统在动态场景中的协作效果。特别是,数据集将关注代理对目标的理解程度,以及代理之间的协调程度。此数据集中支持两种模式:集中式调度器模式和分散式模式。参与者可以选择一个游戏模式,并提交到我们的排行榜。
9.1.1 Benchmark
对于我们的比赛,我们将发布一个基准,CuisineWorld基准,其中包括一个包含可扩展任务定义文件的文本界面,以及一个用于多代理交互和人机交互的界面。我们引入了博弈交互任务,其目标是生成相关的、合适的、多Agent协作策略,以最大化协作效率。我们使用所提出的评估指标CoS来评估协作效率。
“CuisineWorld”数据集由微软、加州大学洛杉矶分校和斯坦福大学收集。比赛的目标是探索不同的,现有的和新颖的,嵌入式LLM和交互式技术如何使用此基准进行,并为多智能体游戏基础设施的任务建立强大的基线。CuisineWorld的数据集包括:
- 一组定义明确的多代理协作任务。
- 一个便于代理交互的API系统。
- 一种自动评估系统。
9.1.2 Task
- 我们提供了一个数据集和相关的基准,称为Microsoft MindAgent,并相应地发布了一个数据集“CuisineWorld”给研究社区。
- 我们将提供基准来评估和排名提交的“MindAgent”算法。我们还将提供使用流行的基础设施生成的基线结果。
9.1.3 Metrics and Judging
多代理协作效率的质量由新的“cos”自动度量(来自MindAgent(Gong等人,2023a))的规定。输出度量的最终评级被计算为多代理系统在所有任务上的所评估的协作效率度量的平均值。将要求人类评估人员对个人的反应进行评级,并对用户与代理的互动的参与度、广度和整体质量提供主观判断。
9.1.4 Evaluation
- 自动评估。我们计划发布一个排行榜,从发布日期(TBA)开始,注册的参与者将被要求提交与数据集“CuisineWorld”(我们公开发布的排行榜数据集)相关的任务的结果。结果提交将在结束日期(TBA)截止。每个团队将被要求提交他们在测试集上生成的结果,以自动评估“cos”指标。
- 在我们的排行榜上的人类评价。排行榜参与者需要提供一个由本地评估脚本生成的提交文件。我们将使用evalAI系统来检查提交文件,并选择性地检查顶级挑战者的代码。因此,团队还必须提交他们的代码,并附上一个关于如何运行代码的自述文件。人的评价将由组织团队进行。
- 赢家公告。我们将公布获奖者名单,并在排行榜上公布参赛作品的最终评分。
9.2 Audio-Video-Language Pre-training Dataset
我们介绍VideoAnalytica:分析视频演示理解的新基准。VideoAnalytica专注于利用视频演示作为辅助手段,以更好地理解嵌入在长格式教学视频中的复杂的高级推理。我们的目标是评估视频语言模型的认知推理能力,使它们超越单纯的识别任务和基本理解,走向更复杂和细致入微的视频理解。至关重要的是,VideoAnalytica强调多种形式的集成,如音频,视频和语言,以及模型应用特定领域知识的能力,以上下文和解释视频中呈现的信息。具体来说,VideoAnalytica涉及两个主要任务:
- 1.视频文本检索:这项任务涉及准确地从教学视频中检索相关文本。挑战在于区分相关和不相关的信息,因此需要深入了解视频内容,并分析演示以检索正确的查询。为了进一步增加这些任务的复杂性,我们将硬否定引入到由大型语言模型生成的数据集中。我们对生成的否定项运行人工验证,并删除使任务无效和不公平的实例(例如,否定项有效)。
- 2.视频辅助信息性问题回答:此任务要求模型根据从视频中提取的信息回答问题。重点是复杂的问题,需要分析推理和视频演示的透彻理解。
为了促进用于分析视频理解的音频-视频-语言代理的开发,我们引入了VideoAnalytica的两个任务的基准排行榜。
- 排行榜参与者需要提交他们的解决方案以供评估。评估将基于模特在两项任务中的表现,结果将显示在排行榜上。要求参与者提交他们的代码,沿着详细说明他们的方法和方法。
- 道德考量:排行榜的重点是理解和解释视频内容,这可能会被用于监控或其他侵犯隐私的应用。因此,必须考虑技术的伦理含义和潜在滥用。我们鼓励参与者在提交的材料中考虑这些方面,并促进人工智能的道德使用。
10 Broader Impact Statement
本文和我们相关的论坛旨在成为创新研究的催化剂,促进合作,推动下一波人工智能应用。通过关注多模态代理,我们强调了人类与AI交互、排行榜和解决方案的未来方向。我们详细介绍了我们为更广泛的社区做出重大贡献的三种方式。
首先,我们希望我们的论坛能够让人工智能研究人员开发出基于游戏、机器人、医疗保健和长视频理解等现实问题的解决方案。具体来说,多模式代理在游戏中的发展可能会带来更身临其境和个性化的游戏体验,从而改变游戏行业。在机器人领域,自适应机器人系统的发展可能会彻底改变从制造业到农业的各个行业,从而可能解决劳动力短缺问题并提高效率。在医疗保健领域,使用LLM和VLM作为诊断试剂或患者护理助理可以提高诊断准确性,改善患者护理,并增加医疗服务的可及性,特别是在服务不足的地区。此外,这些模型解释长格式视频的能力可能具有深远的应用,从加强在线学习到改进技术支持服务。总的来说,我们论坛所涵盖的主题将对世界各地的广泛行业和人类产生重大的下游影响。
其次,我们希望我们的论坛能成为人工智能从业者和研究人员的宝贵资源,作为一个平台,探索和深入理解在各种环境和情况下实施人工智能代理所带来的多样化和复杂的排行榜。例如,这种探索包括了解在为医疗诊断等专业领域开发时与人工智能系统相关的特定限制和潜在危险。在这一领域,人工智能行为中的危险幻觉等问题可能会带来重大风险,这凸显了对精心设计和测试的迫切需求。然而,当考虑为游戏行业制作的AI代理时,这些特定的排行榜可能并不同样相关或值得注意。在这些娱乐领域,开发人员可能会优先考虑解决不同的障碍,例如需要人工智能执行更多的开放式生成并展示创造力,动态适应不可预测的游戏场景和玩家互动。通过参加论坛,与会者将深入了解这些不同的环境如何决定人工智能开发的重点和方向,以及如何最好地定制人工智能解决方案以满足这些不同的需求并克服相关的领导者。
第三,我们活动的各种元素,包括专家演讲,信息丰富的海报,特别是我们两个排行榜的获奖者,将为多式联运代理领域的最新和重要趋势,研究方向和创新概念提供实质性而简洁的概述。这些演讲将概括关键的发现和发展,揭示多模态智能体AI领域的新系统、想法和技术。这种知识的分类不仅有利于我们论坛的与会者,他们希望加深他们在这一领域的理解和专业知识,而且它也是一个充满活力和丰富的资源板。那些访问我们论坛网站的人可以利用这个信息库来发现和了解引导多模态智能体AI未来的前沿进步和创造性想法。我们努力为新来者和退伍军人在该领域的有用的知识基础。通过利用这些资源,我们希望参与者和在线访问者都能够随时了解正在塑造多模式智能体人工智能令人兴奋的格局的变革性变化和新颖方法。
11 Ethical Considerations
多模态Agent人工智能系统有许多应用。除了交互式人工智能之外,基于多模态的模型还可以帮助机器人和人工智能代理驱动内容生成,并协助生产力应用程序,帮助重播,释义,动作预测或合成3D或2D场景。人工智能的基本进步有助于实现这些目标,许多人将受益于更好地理解如何在模拟现实或真实的世界中建模体现和移情。可以说,这些应用程序中有许多可能具有积极的好处。
然而,这项技术也可能被坏人利用。生成内容的人工智能系统可以用来操纵或欺骗人们。因此,根据负责任的AI指导方针开发这项技术非常重要。例如,明确地向用户传达内容是由AI系统生成的,并为用户提供控件以定制这样的系统。Agent AI有可能被用来开发新的方法来检测操纵内容-部分原因是它具有丰富的大型基础模型的幻觉性能-从而帮助解决另一个真实的世界问题。例如,
- 1)在健康主题中,LLM和VLM代理的道德部署,特别是在医疗保健等敏感领域,至关重要。接受偏见数据培训的人工智能代理可能会通过为代表性不足的群体提供不准确的诊断来恶化健康差异。此外,人工智能代理对敏感患者数据的处理引发了严重的隐私和保密问题。
- 2)在游戏行业,人工智能代理可以改变开发人员的角色,将他们的重点从编写非玩家角色的脚本转移到改进代理学习过程。同样,自适应机器人系统可以重新定义制造角色,需要新的技能组合,而不是取代人类工人。负责任地驾驭这些过渡对于尽量减少潜在的社会经济干扰至关重要。
此外,Agent AI侧重于在仿真中学习协作策略,由于分布的变化,如果直接将策略应用于真实的世界,则存在一定的风险。应建立强有力的测试和持续的安全监测机制,以最大限度地减少现实世界中不可预测行为的风险。我们的“VideoAnalytica”数据集是从互联网上收集的,考虑到这不是一个完全代表性的来源,所以我们已经通过了微软和华盛顿大学的道德审查和法律的程序。尽管如此,我们还需要了解这个语料库中可能存在的偏见。数据分布可以以多种方式表征。在这个研讨会中,我们已经捕获了我们数据集中的代理级别分布与其他现有数据集的不同之处。然而,有更多的可以包括在一个单一的数据集或研讨会。我们认为,有必要采取更多的办法或讨论与真实的任务或专题联系起来,并通过提供这些数据或系统。
我们将在项目中专门讨论这些道德问题,探索潜在的缓解策略,并部署负责任的多模态人工智能代理。我们希望通过本文帮助更多的研究者共同回答这些问题。
12 Diversity Statement
通过检查AI代理模型在各个领域的适应性,我们固有地拥有各种各样的排行榜,观点和解决方案。在这种情况下,我们的项目旨在通过探索多模态和代理AI中的各种主题来建立一个多元化的社区。
考虑到这些原则,该项目的重点是先进的多模式系统,在物理和虚拟环境中有效地进行交互,并促进与人类的有效互动。因此,我们打算聘请广泛的专家和从业人员在广泛的技术专业,文化,国家和学术领域讨论重要的主题,包括但不限于:
- 基础模型的应用:开发具有集成模式(音频,图像,文本,传感器输入)的代理,旨在增强其识别和响应能力,以适应各种应用。
- 通用端到端系统:开发使用大规模数据训练的端到端模型,寻求创建通用和适应性强的人工智能解决方案。
- 为模式奠定基础的方法:整合各种模式的信息,加强数据处理的一致性和有效性。·
- 直观的人机界面:开发人与代理之间有效和有意义的交互。
- 驯服LLM/VLM:探索新方法来解决大规模模型中的常见问题,例如其输出中的幻觉和偏差。
我们渴望通过利用我们独特而多样的视角,扩大我们对代理人工智能潜力和局限性的集体理解。我们坚信,这种方法不仅会丰富个人的观点,而且还会增强社区的集体知识,并促进一种更包容多模式人工智能代理所面临的广泛领导者的整体观点。
全文采用的是机器翻译,如果存在某些错误,请大家在留言区指正。欢迎一起交流学习!

Agent 垂直技术社区,欢迎活跃、内容共建,欢迎商务合作。wx: diudiu5555
更多推荐



 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)